2440init.s 2440slib.s這兩個檔案相當於是在ADS1.2開發環境中的簡易bootloader,其實只要輸入這兩個檔名就可搜尋到相關的中文註解說明例如S3C2440 2440init.s分析 2440启动代码注解 ;由於它的組合語言語法與GNU上的組合語言雖然一樣,但是卻有一些假指令,因此我把假指令的相關說明貼於此:arm偽指令 ARM汇编伪指令介绍。
其實在2440init.s中很多代碼是可以拿掉的;特別是那些以左右方括號[ ]作為以if endif,以l做為else的那些判斷式,原因可參考上面連結的相關說明。
今天我們其實重點是擺在2440slib.s這個檔案;2440slib.s注解,然而我個人覺得這個註解寫的並不很清楚,因此我打算自己來搞一遍。
這個檔裡頭都定義了一些和MMU相關聯的底層Routine:例如MMU_EnableICache MMU_DisableICache MMU_EnableDCache MMU_EnableMMU‧‧這裡也列出一些相關連結說明:ARM处理器架构-内存映射 内存管理单元(MMU)介绍 、 FS2410 开发板上启用 MMU 实现虚拟内存管理 、 内存管理单元(MMU)和协处理器CP15介绍 、 s3c2410 MMU(存储器管理单元)讲解 、 ARM920T关闭MMU,cache以及写缓冲区,CP15详解 、 ARM920T的MMU与Cache之操作MMU和Cache的内核启动代码 、 嵌入式Linux学习笔记(四)-内存管理单元mmu。内核关键链接脚本。
在linux kernel有關mmu設定請參考linux/arch/arm/boot/compressed/head.S
對以上的連結看過後就知道其實就是在搞cp15協同處理器;2440slib.s代碼實際內容如下:
目前我只把code擺上來,未來會逐一update
;==========================================
; File Name : 2440slib.s
; Function : S3C2440 (Assembly)
; Date : March 09, 2002
; Revision : Programming start (February 26,2002) -> SOP
; Revision : 03.11.2003 ver 0.0 Attatched for 2440
;==========================================
;Interrupt, FIQ/IRQ disable
NOINT EQU 0xc0 ; 1100 0000
;Check if tasm.exe(armasm -16 ...@ADS 1.0) is used.
GBLL THUMBCODE ;宣告一個全域邏輯變數THUMBCODE 預設值為FALSE
[ {CONFIG} = 16 ;如果CONFIG=16
THUMBCODE SETL {TRUE} ;設定THUMBCODE為TRUE
CODE32 ;假指令CODE32,表示以下的代碼段為ARM 32bit 編碼
l ;else
THUMBCODE SETL {FALSE} ; 設定THUMBCODE為FALSE
] ;endif
MACRO ;巨集宣告
MOV_PC_LR ;巨集名稱
[ THUMBCODE ;如果THUMBCODE為TRUE,則執行下一行,否則跳到下二行else處
bx lr ;同call r14
l ;else
mov pc,lr ;r15<-r14
] ;endif
MEND ;巨集結尾
AREA C$$code, CODE, READONLY ;段宣告 段名稱C$$code 段屬性為代碼段唯讀
EXPORT EnterCritical
EnterCritical
mrs r1, cpsr
str r1, [r0]
orr r1, r1, #NOINT
msr cpsr_cxsf, r1
MOV_PC_LR
;restore cpsr, r0 = address to restore cpsr
EXPORT ExitCritical
ExitCritical
ldr r1, [r0]
msr cpsr_cxsf, r1
MOV_PC_LR
;==============
; CPSR I,F bit
;==============
;int SET_IF(void);
;The return value is current CPSR.
EXPORT SET_IF
SET_IF
;This function works only if the processor is in previliged mode.
mrs r0,cpsr
mov r1,r0
orr r1,r1,#NOINT
msr cpsr_cxsf,r1
MOV_PC_LR
;void WR_IF(int cpsrValue);
EXPORT WR_IF
WR_IF
;This function works only if the processor is in previliged mode.
msr cpsr_cxsf,r0
MOV_PC_LR
;void CLR_IF(void);
EXPORT CLR_IF
CLR_IF
;This function works only if the processor is in previliged mode.
mrs r0,cpsr
bic r0,r0,#NOINT
msr cpsr_cxsf,r0
MOV_PC_LR
EXPORT outportw
outportw strh r0, [r1]
MOV_PC_LR
EXPORT inportw
inportw ldrh r0, [r0]
MOV_PC_LR
;====================================
; MMU Cache/TLB/etc on/off functions
;====================================
R1_I EQU (1<<12)>EXPORT MMU_EnableICache
MMU_EnableICache
mrc p15,0,r0,c1,c0,0
orr r0,r0,#R1_I
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_DisableICache(void)
EXPORT MMU_DisableICache
MMU_DisableICache
mrc p15,0,r0,c1,c0,0
bic r0,r0,#R1_I
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_EnableDCache(void)
EXPORT MMU_EnableDCache
MMU_EnableDCache
mrc p15,0,r0,c1,c0,0
orr r0,r0,#R1_C
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_DisableDCache(void)
EXPORT MMU_DisableDCache
MMU_DisableDCache
mrc p15,0,r0,c1,c0,0
bic r0,r0,#R1_C
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_EnableAlignFault(void)
EXPORT MMU_EnableAlignFault
MMU_EnableAlignFault
mrc p15,0,r0,c1,c0,0
orr r0,r0,#R1_A
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_DisableAlignFault(void)
EXPORT MMU_DisableAlignFault
MMU_DisableAlignFault
mrc p15,0,r0,c1,c0,0
bic r0,r0,#R1_A
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_EnableMMU(void)
EXPORT MMU_EnableMMU
MMU_EnableMMU
mrc p15,0,r0,c1,c0,0
orr r0,r0,#R1_M
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_DisableMMU(void)
EXPORT MMU_DisableMMU
MMU_DisableMMU
mrc p15,0,r0,c1,c0,0
bic r0,r0,#R1_M
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_SetFastBusMode(void)
; FCLK:HCLK= 1:1
EXPORT MMU_SetFastBusMode
MMU_SetFastBusMode
mrc p15,0,r0,c1,c0,0
bic r0,r0,#R1_iA:OR:R1_nF
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;void MMU_SetAsyncBusMode(void)
; FCLK:HCLK= 1:2
EXPORT MMU_SetAsyncBusMode
MMU_SetAsyncBusMode
mrc p15,0,r0,c1,c0,0
orr r0,r0,#R1_nF:OR:R1_iA
mcr p15,0,r0,c1,c0,0
MOV_PC_LR
;=========================
; Set TTBase
;=========================
;void MMU_SetTTBase(int base)
EXPORT MMU_SetTTBase
MMU_SetTTBase
;ro=TTBase
mcr p15,0,r0,c2,c0,0
MOV_PC_LR
;=========================
; Set Domain
;=========================
;void MMU_SetDomain(int domain)
EXPORT MMU_SetDomain
MMU_SetDomain
;ro=domain
mcr p15,0,r0,c3,c0,0
MOV_PC_LR
;=========================
; ICache/DCache functions
;=========================
;void MMU_InvalidateIDCache(void)
EXPORT MMU_InvalidateIDCache
MMU_InvalidateIDCache
mcr p15,0,r0,c7,c7,0
MOV_PC_LR
;void MMU_InvalidateICache(void)
EXPORT MMU_InvalidateICache
MMU_InvalidateICache
mcr p15,0,r0,c7,c5,0
MOV_PC_LR
;void MMU_InvalidateICacheMVA(U32 mva)
EXPORT MMU_InvalidateICacheMVA
MMU_InvalidateICacheMVA
;r0=mva
mcr p15,0,r0,c7,c5,1
MOV_PC_LR
;void MMU_PrefetchICacheMVA(U32 mva)
EXPORT MMU_PrefetchICacheMVA
MMU_PrefetchICacheMVA
;r0=mva
mcr p15,0,r0,c7,c13,1
MOV_PC_LR
;void MMU_InvalidateDCache(void)
EXPORT MMU_InvalidateDCache
MMU_InvalidateDCache
mcr p15,0,r0,c7,c6,0
MOV_PC_LR
;void MMU_InvalidateDCacheMVA(U32 mva)
EXPORT MMU_InvalidateDCacheMVA
MMU_InvalidateDCacheMVA
;r0=mva
mcr p15,0,r0,c7,c6,1
MOV_PC_LR
;void MMU_CleanDCacheMVA(U32 mva)
EXPORT MMU_CleanDCacheMVA
MMU_CleanDCacheMVA
;r0=mva
mcr p15,0,r0,c7,c10,1
MOV_PC_LR
;void MMU_CleanInvalidateDCacheMVA(U32 mva)
EXPORT MMU_CleanInvalidateDCacheMVA
MMU_CleanInvalidateDCacheMVA
;r0=mva
mcr p15,0,r0,c7,c14,1
MOV_PC_LR
;void MMU_CleanDCacheIndex(U32 index)
EXPORT MMU_CleanDCacheIndex
MMU_CleanDCacheIndex
;r0=index
mcr p15,0,r0,c7,c10,2
MOV_PC_LR
;void MMU_CleanInvalidateDCacheIndex(U32 index)
EXPORT MMU_CleanInvalidateDCacheIndex
MMU_CleanInvalidateDCacheIndex
;r0=index
mcr p15,0,r0,c7,c14,2
MOV_PC_LR
;void MMU_WaitForInterrupt(void)
EXPORT MMU_WaitForInterrupt
MMU_WaitForInterrupt
mcr p15,0,r0,c7,c0,4
MOV_PC_LR
;===============
; TLB functions
;===============
;voic MMU_InvalidateTLB(void)
EXPORT MMU_InvalidateTLB
MMU_InvalidateTLB
mcr p15,0,r0,c8,c7,0
MOV_PC_LR
;void MMU_InvalidateITLB(void)
EXPORT MMU_InvalidateITLB
MMU_InvalidateITLB
mcr p15,0,r0,c8,c5,0
MOV_PC_LR
;void MMU_InvalidateITLBMVA(U32 mva)
EXPORT MMU_InvalidateITLBMVA
MMU_InvalidateITLBMVA
;ro=mva
mcr p15,0,r0,c8,c5,1
MOV_PC_LR
;void MMU_InvalidateDTLB(void)
EXPORT MMU_InvalidateDTLB
MMU_InvalidateDTLB
mcr p15,0,r0,c8,c6,0
MOV_PC_LR
;void MMU_InvalidateDTLBMVA(U32 mva)
EXPORT MMU_InvalidateDTLBMVA
MMU_InvalidateDTLBMVA
;r0=mva
mcr p15,0,r0,c8,c6,1
MOV_PC_LR
;=================
; Cache lock down
;=================
;void MMU_SetDCacheLockdownBase(U32 base)
EXPORT MMU_SetDCacheLockdownBase
MMU_SetDCacheLockdownBase
;r0= victim & lockdown base
mcr p15,0,r0,c9,c0,0
MOV_PC_LR
;void MMU_SetICacheLockdownBase(U32 base)
EXPORT MMU_SetICacheLockdownBase
MMU_SetICacheLockdownBase
;r0= victim & lockdown base
mcr p15,0,r0,c9,c0,1
MOV_PC_LR
;=================
; TLB lock down
;=================
;void MMU_SetDTLBLockdown(U32 baseVictim)
EXPORT MMU_SetDTLBLockdown
MMU_SetDTLBLockdown
;r0= baseVictim
mcr p15,0,r0,c10,c0,0
MOV_PC_LR
;void MMU_SetITLBLockdown(U32 baseVictim)
EXPORT MMU_SetITLBLockdown
MMU_SetITLBLockdown
;r0= baseVictim
mcr p15,0,r0,c10,c0,1
MOV_PC_LR
;============
; Process ID
;============
;void MMU_SetProcessId(U32 pid)
EXPORT MMU_SetProcessId
MMU_SetProcessId
;r0= pid
mcr p15,0,r0,c13,c0,0
MOV_PC_LR
END
2010年4月28日 星期三
2010年4月20日 星期二
GRUB Tracing 2
先列出configure.ac的巨集:截錄自gcc/gdb/make/autotool 文件/教學
AC_INIT(FILE)這個巨集用來檢查原始碼所在的路徑,autoscan會自動產生,我們不必修改它。
AM_INIT_AUTOMAKE(PACKAGE,VERSION)使用 Automake 所必備的巨集,PACKAGE是我們所要產生軟體套件的名稱,VERSION 是版本編號。
AC_CONFIG_AUX_DIR(dir)configure 系統時所使用的所有檔案( install-sh,config.sub,config.guess )若不想放在 configure 所在的目錄下, 可以利用此巨集指定在子目錄中
AC_CONFIG_HEADER(header.h) autoheader 會根據 AC_CHECK_HEADERS、AC_DEFINE 等巨集,產生 header.h.in , configure 參考此檔產生 header.h, 套件中的 header files只要含入header.h,即可解決編譯時大量的 '-D' 選項 。
AC_PROG_CC檢查系統可用的 C 編譯器,如果原始程式是用 C 寫的就需要這個巨集。其他程式檢查巨集請查看 autoconf/acprograms
AC_PROG_INSTALL檢察系統內是否有 BSD 相容 install 工具程式, 否則以 automake 的install-sh 替代。
AC_SUBST(VARIABLE) configure 程式會將 AC_OUTPUT 巨集所列出檔案中與指定變數名稱相同的位置,取代為該變數的值。
AC_CHECK_HEADERS( header.h)檢查系統中是否存在 header.h
AC_DEFINE(variable, define , comment)定義 C preprocessor variable, 可省略後兩項參數, 但預先必須在acconfig.h 中定義。ex: #undef USE_DNS
AC_DEFINE_UNQUOTED(variable, 可展開的 definem, comment )類似 AC_DEFINE , 其中的 define 若包含變數, 則會以內容展開變數ex:
AC_CONFIG_HEADER( conf.h )
AC_CHECK_HEADERS( unistd.h )
AC_DEFINE(USE_DNS, 1 , 使用DNS)
AC_DEFINEi_UNQUOTED(EDITOR, "$EDITOR", editor 的路徑)
則 autoheader 產生 conf.h.in 內含:
------------------------------------------------------------
/* Define as 1 if you have unistd.h */
#define HAVE_UNISTD_H 0
/* 使用DNS */
#undef USE_DNS
/* editor 的路徑 */
#undef EDITOR
若 configure 時, 若有 unistd.h、及指定 EDITOR=/usr/bin/vi 則
產生之 conf.h 如下
-----------------------------------------------------------
/* Define as 1 if you have unistd.h */
#define HAVE_UNISTD_H 1
/* 使用DNS */
#define USE_DNS 1
/* editor 的路徑 */
#define EDITOR /usr/bin/vi
AC_CHECK_PROG(variable,program,value-if-found,value-if-found,path1:path2)依指定路徑 path1:path2 尋找指定的 program, 若找到將 variable指定為 value-if-found, 若沒有找到 variable 指定為value-if-not-found,設定 variable 使用檔案的絕對檔案名稱。
AC_PATH_PROG(variable, program, value-if-not-found, path1:path2)依指定路徑 path1:path2 尋找指定的 program, 若找到將 variable指定為其完整路徑, 若沒有找到 variable 指定為 value-if-not-found。
AC_CANONICAL_HOST檢查系統類型, 並將其值存入 $host 變數
AC_CHECK_FUNCS(funcs, action-if-found, action-if-not-found)找尋是否有指定的 function 存在, 若存在執行 active-if-found 之 shell command, 反之則執行 active-if-not-found。可被檢查函式請參考autoconf/acfunctions
AC_ARG_ENABLE( feature,help-string,action-if-given,action-if-not-given)如果執行 configure 給定 --enable-feature 或 --disable-feature, 則會啟動相關的 action , enable 會執行 action-if-given, disable 會執行action-if-not-given。通常與 AC_DEFINE 搭配, 定義是否編譯某一項功能。
AC_OUTPUT(FILE)設定 configure 所要產生的檔案,如果是 Makefile 的話,configure便會把它檢查出來的結果 Makefile.in 檔然後產生合適的 Makefile。
ex:
configure.in 片段 Makefile.in 片段
--------------------------------------------------------------
FOO="hello" CFLAGS = -D@FOO@
AC_SUBST(FOO)
則執行 configure 後會產生 Makefile 包含以下片段: CFLAGS = -Dhello
* 2. 編輯 Makefilea.am , automake 根據 configure.in 中的巨集,將 Makefile.am轉變成 Makefile.in, 執行 automake --add-missing --copy 即可。
--add-missing 將包裝好 configure 所需之檔案補齊( 預設為 link 的方式 )
--copy 所需的檔案以 copy 的方式補齊
automake 支援、認可的 configure.in 巨集
----------------------------------------------------------------------
AC_INIT_AUTOMAKE(package, version)定義 PACKAGE、VERSION 兩變數
AM_CONFIG_HEADER( header.h )讓 automake 產生可自動再生成 header.h 的規則,使用此巨集必須先定義stamp-h.in, 用於標記 header.h 產生的時間。
AC_CANONICAL_HOST
AC_CHECK_TOOL automake 會確認 config.guess 及 config.sub 的存在。config.guess 用於猜測系統類型、config.sub用於提供檢查工具。
Makefile.am 選項說明
----------------------------------------------------------------------------
AUTOMAKE_OPTIONS設定 automake 的選項。Automake 主要是幫助開發 GNU 軟體的人員維護軟體套件,所以在執行 automake 時,會檢查目錄下是否存在標準GNU 軟體套件中應具備的文件檔案,例如 'NEWS'、'AUTHOR'、'ChangeLog'等文件檔。設成 foreign 時,automake 會改用一般軟體套件的標準來檢查。
SUBDIRS automake 會產生能夠遞迴進入指定目錄的 Makefile 規則。
bin_PROGRAMS定義我們所要產生的執行檔檔名。如果要產生多個執行檔,每個檔名用空白字元隔開。
hello_SOURCES定義 'hello' 這個執行檔所需要的原始檔。如果 'hello' 這個程式是由多個原始檔所產生,必須把它所用到的原始檔都列出來,以空白字元隔開。假設 'hello' 這個程式需要 'hello.c'、'main.c'、'hello.h'三個檔案的話,則定義hello_SOURCES= hello.c main.c hello.h
如果我們定義多個執行檔,則對每個執行檔都要定義相對的 filename_SOURCES。
pkgdata_DATA將 pkgdata_DATA 所指定的檔案安裝到 pkgdatadir 指定的目錄,*_DATA 對應*dir,如 localstate_DATA 安裝至 localstatedir。
EXTRA_DIST在 make dist 時將指定的檔案一起打包。
AC_PREREQ確保使用的是足夠新的Autoconf版本。如果用於創建configure的Autoconf的版本比version 要早,就在標準錯誤輸出列印一條錯誤消息並不會創建configure。
AC_CONFIG_SRCDIR([main.c])用來偵測所指定的源碼檔是否存在,來確定源碼目錄的有效性。
AC_CONFIG_HEADER([config.h])用於生成config.h檔,以便autoheader使用。
* 3. 建構 GNU build 系統aclocal -> autoheader -> autoconf -> automake
GRUB中文指南
我想到此就可以知道大概了;可以直接到makefile
AC_INIT(FILE)這個巨集用來檢查原始碼所在的路徑,autoscan會自動產生,我們不必修改它。
AM_INIT_AUTOMAKE(PACKAGE,VERSION)使用 Automake 所必備的巨集,PACKAGE是我們所要產生軟體套件的名稱,VERSION 是版本編號。
AC_CONFIG_AUX_DIR(dir)configure 系統時所使用的所有檔案( install-sh,config.sub,config.guess )若不想放在 configure 所在的目錄下, 可以利用此巨集指定在子目錄中
AC_CONFIG_HEADER(header.h) autoheader 會根據 AC_CHECK_HEADERS、AC_DEFINE 等巨集,產生 header.h.in , configure 參考此檔產生 header.h, 套件中的 header files只要含入header.h,即可解決編譯時大量的 '-D' 選項 。
AC_PROG_CC檢查系統可用的 C 編譯器,如果原始程式是用 C 寫的就需要這個巨集。其他程式檢查巨集請查看 autoconf/acprograms
AC_PROG_INSTALL檢察系統內是否有 BSD 相容 install 工具程式, 否則以 automake 的install-sh 替代。
AC_SUBST(VARIABLE) configure 程式會將 AC_OUTPUT 巨集所列出檔案中與指定變數名稱相同的位置,取代為該變數的值。
AC_CHECK_HEADERS( header.h)檢查系統中是否存在 header.h
AC_DEFINE(variable, define , comment)定義 C preprocessor variable, 可省略後兩項參數, 但預先必須在acconfig.h 中定義。ex: #undef USE_DNS
AC_DEFINE_UNQUOTED(variable, 可展開的 definem, comment )類似 AC_DEFINE , 其中的 define 若包含變數, 則會以內容展開變數ex:
AC_CONFIG_HEADER( conf.h )
AC_CHECK_HEADERS( unistd.h )
AC_DEFINE(USE_DNS, 1 , 使用DNS)
AC_DEFINEi_UNQUOTED(EDITOR, "$EDITOR", editor 的路徑)
則 autoheader 產生 conf.h.in 內含:
------------------------------------------------------------
/* Define as 1 if you have unistd.h */
#define HAVE_UNISTD_H 0
/* 使用DNS */
#undef USE_DNS
/* editor 的路徑 */
#undef EDITOR
若 configure 時, 若有 unistd.h、及指定 EDITOR=/usr/bin/vi 則
產生之 conf.h 如下
-----------------------------------------------------------
/* Define as 1 if you have unistd.h */
#define HAVE_UNISTD_H 1
/* 使用DNS */
#define USE_DNS 1
/* editor 的路徑 */
#define EDITOR /usr/bin/vi
AC_CHECK_PROG(variable,program,value-if-found,value-if-found,path1:path2)依指定路徑 path1:path2 尋找指定的 program, 若找到將 variable指定為 value-if-found, 若沒有找到 variable 指定為value-if-not-found,設定 variable 使用檔案的絕對檔案名稱。
AC_PATH_PROG(variable, program, value-if-not-found, path1:path2)依指定路徑 path1:path2 尋找指定的 program, 若找到將 variable指定為其完整路徑, 若沒有找到 variable 指定為 value-if-not-found。
AC_CANONICAL_HOST檢查系統類型, 並將其值存入 $host 變數
AC_CHECK_FUNCS(funcs, action-if-found, action-if-not-found)找尋是否有指定的 function 存在, 若存在執行 active-if-found 之 shell command, 反之則執行 active-if-not-found。可被檢查函式請參考autoconf/acfunctions
AC_ARG_ENABLE( feature,help-string,action-if-given,action-if-not-given)如果執行 configure 給定 --enable-feature 或 --disable-feature, 則會啟動相關的 action , enable 會執行 action-if-given, disable 會執行action-if-not-given。通常與 AC_DEFINE 搭配, 定義是否編譯某一項功能。
AC_OUTPUT(FILE)設定 configure 所要產生的檔案,如果是 Makefile 的話,configure便會把它檢查出來的結果 Makefile.in 檔然後產生合適的 Makefile。
ex:
configure.in 片段 Makefile.in 片段
--------------------------------------------------------------
FOO="hello" CFLAGS = -D@FOO@
AC_SUBST(FOO)
則執行 configure 後會產生 Makefile 包含以下片段: CFLAGS = -Dhello
* 2. 編輯 Makefilea.am , automake 根據 configure.in 中的巨集,將 Makefile.am轉變成 Makefile.in, 執行 automake --add-missing --copy 即可。
--add-missing 將包裝好 configure 所需之檔案補齊( 預設為 link 的方式 )
--copy 所需的檔案以 copy 的方式補齊
automake 支援、認可的 configure.in 巨集
----------------------------------------------------------------------
AC_INIT_AUTOMAKE(package, version)定義 PACKAGE、VERSION 兩變數
AM_CONFIG_HEADER( header.h )讓 automake 產生可自動再生成 header.h 的規則,使用此巨集必須先定義stamp-h.in, 用於標記 header.h 產生的時間。
AC_CANONICAL_HOST
AC_CHECK_TOOL automake 會確認 config.guess 及 config.sub 的存在。config.guess 用於猜測系統類型、config.sub用於提供檢查工具。
Makefile.am 選項說明
----------------------------------------------------------------------------
AUTOMAKE_OPTIONS設定 automake 的選項。Automake 主要是幫助開發 GNU 軟體的人員維護軟體套件,所以在執行 automake 時,會檢查目錄下是否存在標準GNU 軟體套件中應具備的文件檔案,例如 'NEWS'、'AUTHOR'、'ChangeLog'等文件檔。設成 foreign 時,automake 會改用一般軟體套件的標準來檢查。
SUBDIRS automake 會產生能夠遞迴進入指定目錄的 Makefile 規則。
bin_PROGRAMS定義我們所要產生的執行檔檔名。如果要產生多個執行檔,每個檔名用空白字元隔開。
hello_SOURCES定義 'hello' 這個執行檔所需要的原始檔。如果 'hello' 這個程式是由多個原始檔所產生,必須把它所用到的原始檔都列出來,以空白字元隔開。假設 'hello' 這個程式需要 'hello.c'、'main.c'、'hello.h'三個檔案的話,則定義hello_SOURCES= hello.c main.c hello.h
如果我們定義多個執行檔,則對每個執行檔都要定義相對的 filename_SOURCES。
pkgdata_DATA將 pkgdata_DATA 所指定的檔案安裝到 pkgdatadir 指定的目錄,*_DATA 對應*dir,如 localstate_DATA 安裝至 localstatedir。
EXTRA_DIST在 make dist 時將指定的檔案一起打包。
AC_PREREQ確保使用的是足夠新的Autoconf版本。如果用於創建configure的Autoconf的版本比version 要早,就在標準錯誤輸出列印一條錯誤消息並不會創建configure。
AC_CONFIG_SRCDIR([main.c])用來偵測所指定的源碼檔是否存在,來確定源碼目錄的有效性。
AC_CONFIG_HEADER([config.h])用於生成config.h檔,以便autoheader使用。
* 3. 建構 GNU build 系統aclocal -> autoheader -> autoconf -> automake
GRUB中文指南
我想到此就可以知道大概了;可以直接到makefile
原來....我也是生存在這種輪迴之中
今天爬文不小心看到以下這一小段:
標題:大學生不如美女值錢.
苦工-----資本家----美女----苦工
這樣的資金流動在中國比較流行.
苦工勞動生產產品,資本家得到最大利益,
得到最大利益的資本家,本性需求高,花錢包美女
美女,愛美,愛花錢,買產品,
在這個資產迴圈中美女,是一重要因素.當然核心不是資本家.
看了之後‧‧‧‧‧‧
我想人生中至少也有美好的事物,若是硬要以物質衡量,那心靈方面的滿足又算什麼?
標題:大學生不如美女值錢.
苦工-----資本家----美女----苦工
這樣的資金流動在中國比較流行.
苦工勞動生產產品,資本家得到最大利益,
得到最大利益的資本家,本性需求高,花錢包美女
美女,愛美,愛花錢,買產品,
在這個資產迴圈中美女,是一重要因素.當然核心不是資本家.
看了之後‧‧‧‧‧‧
我想人生中至少也有美好的事物,若是硬要以物質衡量,那心靈方面的滿足又算什麼?
2010年4月15日 星期四
學習GRUB Programming初啼
GRUB(Gran Unified Bootloader)是個bootloader,為何我對它這樣著迷,其實應該說道理還是一樣,它看起來不大,而且目前已經可以支援ATA SATA USB CDROM 等開機,因此絕對可以學到很多實作及概念並認識各式檔案系統如何運作,未來將OS安裝在USB DEVICE的狀況將會越來越常見 .重點當然也是因為它和linux kernel比較起來小很多,我想trace code應該也會比較得心應手.說真的像linux kernel那麼大也別想用source insight來管理,就連U-Boot都有點吃力了.所以越大的project還是要在linux環境來trace code,較沒有效能上的疑慮.然而我實際編譯一次後才發現它的檔案量還真不少,install到系統的模組也有1百多個;網上相關的編程教學也少的可憐;看來是要自立自強了。
一開始只知道它的評價比LILO好,其他說真的還一無所知.首先先來點開味菜ㄅ:雖然本文並非討論GRUB如何使用,但trace code需要的狀況還是會稍微提到。
configure及makefile;這個makefile是執行configure shell script後產生的;這是很正常的程序,只是我覺得寫這個shell script的人不正常。
然而實際上configure這個shell script也是自動產生的;說著說著好像越來越模糊了。說真的我越來越怕看到(自動)這兩個字了;因為那表示又有一些相關技術要k了。果然網上隨便輸入"automake" "autoconf" "makefile" "makefile.am" "makefile.in"等關鍵字保證又是一堆資料等著你去把相關知識給整合起來。要完成一個自動產生的makefile,流程大概如下:
1.autoscan 產生一個 configure.scan,更名為 configure.in
2.修改 configure.in 的內容
3.執行 aclocal 和 autoconf,分別會產生 aclocal.m4 及 configure 兩個檔案
4.使用編輯器,建立 Makefile.am 檔
5.使用 automake --add-missing 將 Makefile.in 產生出來
6.執行 ./configure,產生makefile
然而在grub project裡頭將以上幾個步驟寫成autogen.sh shell script內容如下:而且它的實作方式稍微不同,它不採用makefile.am
#! /bin/sh
set -e
aclocal
autoconf #到此產生configure
autoheader
# FIXME: automake doesn't like that there's no Makefile.am
automake -a -c -f true
echo timestamp > stamp-h.in
python util/import_gcry.py lib/libgcrypt/ .
for rmk in conf/*.rmk ${GRUB_CONTRIB}/*/conf/*.rmk
do
if test -e $rmk ; then
ruby genmk.rb < $rmk > `echo $rmk sed 's/\.rmk$/.mk/'`
fi
done
sh gendistlist.sh > DISTLIST
exit 0
雖然不到20行,但是卻牽扯到python、sed、ruby,所以我說學習shell programming並不簡單,應該是說你不可能只學習一種script語言;這樣會使你創作能力降低,但要一下子就搞這麼多東西;我想我會瘋掉、會瘋掉。更何況有用的script還有像perl、awk‧‧‧就是說光想在linux上programming;並不是想像中那樣;但script畢竟是比較簡單;雖然很多人總寫出一堆令人費解的敘述;寫到這裡不禁感嘆:年事已高的我,未來的路還很長。
無論我們是否要搞懂這個autogen.sh,至少要知道這個檔是否對未來整個專案的理解有很大關聯;所以實際去執行./configure後直接把makefile打開來看;果不其然還真有寸步難行之感。所以還是要乖乖就範,把這個autogen.sh給搞懂;因為它和之前描述的那6個步驟作法不同,也沒有執行autoscan所以沒有configure.scan,因此就不會有configure.in。不使用makefile.am,有看到執行automake,但是卻早有makefile.in這個檔案;總之用ㄌ一些自動化的工具卻不走正統路線;所以只好再去找一些相關資訊,例如:GNU Coding Standards FreeBSD Porter 手册 autoconf 和 automake 生成 Makefile 文件。
原來GRUB使用configure.ac,我想接下來應該是把重點擺到這個檔案上。因為aclocal是一個perl 腳本程式,它的定義是:aclocal - create aclocal.m4 by scanning configure.ac 。
終於好不容易找到了以下連結可供參考:Configure Makefile.am Makefile.in Makefile文件之間關係 automake Introduction英文 簡體 GRUB 運作原理
一開始只知道它的評價比LILO好,其他說真的還一無所知.首先先來點開味菜ㄅ:雖然本文並非討論GRUB如何使用,但trace code需要的狀況還是會稍微提到。
configure及makefile;這個makefile是執行configure shell script後產生的;這是很正常的程序,只是我覺得寫這個shell script的人不正常。
然而實際上configure這個shell script也是自動產生的;說著說著好像越來越模糊了。說真的我越來越怕看到(自動)這兩個字了;因為那表示又有一些相關技術要k了。果然網上隨便輸入"automake" "autoconf" "makefile" "makefile.am" "makefile.in"等關鍵字保證又是一堆資料等著你去把相關知識給整合起來。要完成一個自動產生的makefile,流程大概如下:
1.autoscan 產生一個 configure.scan,更名為 configure.in
2.修改 configure.in 的內容
3.執行 aclocal 和 autoconf,分別會產生 aclocal.m4 及 configure 兩個檔案
4.使用編輯器,建立 Makefile.am 檔
5.使用 automake --add-missing 將 Makefile.in 產生出來
6.執行 ./configure,產生makefile
然而在grub project裡頭將以上幾個步驟寫成autogen.sh shell script內容如下:而且它的實作方式稍微不同,它不採用makefile.am
#! /bin/sh
set -e
aclocal
autoconf #到此產生configure
autoheader
# FIXME: automake doesn't like that there's no Makefile.am
automake -a -c -f true
echo timestamp > stamp-h.in
python util/import_gcry.py lib/libgcrypt/ .
for rmk in conf/*.rmk ${GRUB_CONTRIB}/*/conf/*.rmk
do
if test -e $rmk ; then
ruby genmk.rb < $rmk > `echo $rmk sed 's/\.rmk$/.mk/'`
fi
done
sh gendistlist.sh > DISTLIST
exit 0
雖然不到20行,但是卻牽扯到python、sed、ruby,所以我說學習shell programming並不簡單,應該是說你不可能只學習一種script語言;這樣會使你創作能力降低,但要一下子就搞這麼多東西;我想我會瘋掉、會瘋掉。更何況有用的script還有像perl、awk‧‧‧就是說光想在linux上programming;並不是想像中那樣;但script畢竟是比較簡單;雖然很多人總寫出一堆令人費解的敘述;寫到這裡不禁感嘆:年事已高的我,未來的路還很長。
無論我們是否要搞懂這個autogen.sh,至少要知道這個檔是否對未來整個專案的理解有很大關聯;所以實際去執行./configure後直接把makefile打開來看;果不其然還真有寸步難行之感。所以還是要乖乖就範,把這個autogen.sh給搞懂;因為它和之前描述的那6個步驟作法不同,也沒有執行autoscan所以沒有configure.scan,因此就不會有configure.in。不使用makefile.am,有看到執行automake,但是卻早有makefile.in這個檔案;總之用ㄌ一些自動化的工具卻不走正統路線;所以只好再去找一些相關資訊,例如:GNU Coding Standards FreeBSD Porter 手册 autoconf 和 automake 生成 Makefile 文件。
原來GRUB使用configure.ac,我想接下來應該是把重點擺到這個檔案上。因為aclocal是一個perl 腳本程式,它的定義是:aclocal - create aclocal.m4 by scanning configure.ac 。
終於好不容易找到了以下連結可供參考:Configure Makefile.am Makefile.in Makefile文件之間關係 automake Introduction英文 簡體 GRUB 運作原理
2010年4月14日 星期三
DOS記憶體管理
DOS不管電腦擴充了幾MB的記憶體, 當你用MEM.EXE 來觀察時, 傳統記憶體(Conventional memory) 固定都只有640K Bytes。這640KB 就是一般應用程式所能使用的範圍。如果你使用5.0 版以前的DOS,進入中文糸統, 再要執行其他較佔記憶體的應用程式時, 就有可能產生 "記憶體不足" 的訊息, 不管你在640K以外還有多少記憶體。而現在DOS 5.0 最為人稱道的地方, 就是它提供了許多管理記憶體的方法, 讓程式有更多的記憶體空間可以運用。
DOS 5.0 提供的記憶體管理, 指的是位址為640K以上的記憶體。如果你的電腦只有640K 的RAM, 那麼DOS 5.0 對你就沒有多大用處。一般電腦最基本配備有1 Mega的記憶體, 就有384 K 的延伸記憶體可以運用。記憶體容量愈大, 運用範圍愈廣。像WINDOW這類多工軟體, 就需要龐大的記憶體來增加其速度。
640K的傳統記憶體
640K的限制由何處來的? 這必須回顧PC和CPU 的歷史。CPU 的定址能力, 是由硬體線路所限定的。在早期APPLEⅡ 使用的6502 CPU, 它是8 位元的微處理機, 故具有8 條的資料線路。其資料處理是以位元組(Byte)為單位, 每一個Byte可表示2^8 = 256 種數字。同時它用兩個Byte的組合來指示記憶體的位址。因此它須具有16條的位址線路, 共可表達2^16 = 65536 =64K 種的位址。換句話說, 16條的位址線路的定址能力的最高限制就是64KB 。1978年Intel 公司推出16位元的8086微處理機, 以16位元的字組( Word,相當於兩個Byte) 為資料處理的單位。位址線路則增加到20條;因此必須用兩個Word來表示記憶體的位址。這兩個Word如果也採用線性對映的定址方式, 那麼共可表示: 2 ^32 = 2^2x2^10x2^10x2^10 = 4 x K x K x K = 4G 種的位址!這在當時看來是軟硬體皆不可能達成的數字。更何況位址線又沒有32條,只有20條而已, 就是說實際定址能力的最高限制是2^20 Bytes = 1MB。那時的RAM 也很昂貴, 所以認為1MB (是64KB 的16倍) 是夠大的了。
因此8086採取了重疊對映的定址方式 (悲劇的開始!)。由兩個Word以XXXX:YYYY 的方式來組成一個20位元的線性位址, 前者為節區段位址(Segment),後面稱偏移段位址(Offset)。
公式如下:Address = Segment * 16 + Offset
格式:Segment:offset =>(段位址):(偏移位址) =>1 2 3 4 : 2 3 4 5
1 2 3 4 0
+2 3 4 5
(真實記憶體位址) --------------
1 4 6 8 5 h
以上的記憶體位址是16進位數字, 在數字後面附加小寫h 來表示。例如: 640K (10進位) = A0000 h = A000:0000 等到1982年, 藍色巨人IBM 推出最早型的IBM PC XT,以Intel 8088微處理機作為CPU,8088與8086都只有20條位址線(A0~A19) 。IBM 對可定址的1MB 記憶體位址做個規劃, 其中最前面的640K RAM供DOS 與應用程式使用, 這塊區域叫主記憶體(Base Memory) 或傳統記憶體。640K到1MB 的記憶體區域保留給外加擴充的界面卡和BIOS使用, 這塊區域叫上層記憶體 (Upper Memory),一般應用程式不可輕易動用。這也就是DOS和一般應用程式最多只能控制640K的原因。
1983年Intel 推出了80286, IBM立刻選用為最新的CPU,於1984年底推出IBM PC AT(AT是Advanced Technology 先進技術之意) 。80286 是真正的16位元微處理機(CPU內部與I/O 均以16位元處理),運作速度更快。它有24條位址線, 故最多可存取2^24 = 16MB 的記憶體。
事實上80286 採用了兩種定址模式:一、真實模式 (Real Mode)在此模式下,286使用和8086/8088 相同的重疊對映的定址方式。這是為了讓原有的DOS 和應用程式能在PC AT 上相容使用。因此, 在真實模式下, 也只能控制1MB 記憶體而已。二、虛擬保護模式 (Virtual Protected Mode)在保護模式下, 才能隨意使用1MB 以上的記憶體。後來陸續推出32位元的80386和80486 (皆有32條位址線),又提供了功能更強的保護模式。但是也都保留了真實模式, 以滿足往前的相容。MS-DOS改版至今, 一直是在真實模式下運作。對於在286/386/486超過1024K 的記憶體, 只能拿來當虛擬磁碟機, 或硬碟快取程式(Disk cache), 或者使用一些其他的驅動程式 (如EMM或XMM) 來支援, 而不能像在傳統記憶體一樣方便的使用。 擴展記憶體和延伸記憶體早在XT時代, 一些大型軟體就有記憶體不足的困擾了。因此, Lotus/Intel/Microsoft三家公司共同制定了一個擴展記憶體規格(Expanded Memory Spec.;EMS),採用記憶庫切換(bank swapping) 的方式來指定位置段落。擴展記憶體規格(EMS) 包含了硬體的EMS 擴充界面卡, 和軟體的管理程式(Expanded Memory Manager ;EMM)。這種EMS 記憶體就是擴展記憶體 (Expanded Memory) 。
隨著PC AT 的普及, 程式可透過保護模式存取位址為1MB 以上的記憶體。這些位址為1MB 以上的記憶體就稱為延伸記憶體( Extended Memory) 。為了避免各程式取用的延伸記憶體的區域相衝突, Mircrosoft、Intel、Lotus等公司制定了一個延伸記憶體規格(Extended Memory Spec. ;XMS), 規定了高記憶區、上層記憶體與延伸記憶體的存取標準。一般的程式只要呼叫管理程式(eXtended Memory Manager ;XMM), 就能有效運用XMS 的資源。像MS-DOS 5.0的HIMEM.SYS 就是符合XMS 標準的管理程式。
Expanded(擴展)表示向橫的方向擴展, Extended則是縱向的延伸。EMS 和XMS 不同的地方是: EMS 是XT時代發展出的規格; 擴展記憶體、EMS 卡是隨著EMS 發表的, 它的重點是在1024K 的定址範圍內使用更多的記憶體, 實際的定址限制仍是1024K。
XMS 則是在有了延伸記憶體之後才訂定的規格, 用來管理640K以外的記憶體。延伸記憶體可用軟體方式模擬成EMS 標準, 讓只支援EMS 的較早期程式也能夠使用。如果你要擴充記憶體容量, 且你的主機板上仍有空的記憶體插槽,就可直接買RAM 來插, 即增加延伸記憶體, 就可做為XMS 或EMS 使用,也比EMS 卡便宜。若您的主機板上已無空的記憶體插槽, 那只好買EMS卡來插在擴充槽上了。有些EMS 卡上有開關, 可將卡上的記憶體調成延伸記憶體; 否則就只能當做擴展記憶體了。
EMS 使用記憶庫切換的方法, 在有限位址內使用更多的記憶體, 事實上只解決資料的問題, 要執行程式仍然很麻煩。這方法和SuperVGA的切頁方式類似, 若用SuperVGA則較容易理解 "切頁對映" 的觀念。PC分配給彩色螢幕的視訊對映位址只有64K (A0000h ~ AFFFFh),而SuperVGA若要顯示1024x768x256色的模式, 則需要768K 的記憶體(所以SuperVGA卡要有1MB RAM), 64K 的位址如何夠用呢? SuperVGA就把這1MB RAM 分成16個64K 等分,CPU每次可存取其中的64K,而用一個暫存器來選擇切換。
高記憶區 HMA 與 上層記憶區塊 UMB 雖然一般程式在真實模式下只能使用640K, 但DOS 5.0 提供了HMA和UMB 記憶區的使用, 在真實模式下突破了640K的限制。約64K 的高記憶區 ( HMA, High Memory Area )真實模式下的最大位址可達FFFF:FFFF = 10FFEF h的位址, 這已超過真實模式的1 Mega上限。所以多出來的100000h 到10FFEFh 就會捲繞(wrapping)重新對映到位址0 ~FFEFh 的地方。對286 以上的CPU,如果將位址線A20 致能(enable), 則不會發生捲繞, 多出來的這64K-16bytes就是HMA 。一般說HMA 有64K,其實是64K - 16 bytes 。上層記憶區塊 ( UMB, Upper Memory Block )PC把位址為640K到1MB (即A0000 h ~FFFFF h) 的上層記憶體, 規劃給界面卡和BIOS使用。這部分的ROM 除了系統BIOS是在主機母板之外, 其他的ROM (或RAM) 則是在使用該位址的界面卡上。
通常我們都只用到上層記憶體的位址的一部分而已, 其他可用的位址就浪費掉了。使用DOS 5.0 的EMM386.EXE, 可以將這些沒有使用到的上層記憶體位址, 改成對映到延伸記憶體上, 就叫做UMB 。這樣你在真實模式下, 就又多出一部分可使用的位址了。
這些多出來的UMB 記憶體, 通常用來存放各種佔記憶體的驅動程式和常駐程式, 儘量空出傳統記憶體空間來執行大型程式。
UMB 依據個人週邊配備和設定的不同, 約可多出60K~200K 左右的可使用位址。EMM386.EXE就是管理UMB 的工具。QEMM386 (Quarterdeck公司的軟體) 功能比EMM386強大,不用加參數即可規劃出最大的可用UMB, 因此很多人使用。但你還是要瞭解EMM386, 以便可隨時更替, 因為EMM386的功能較穩定。
使用EMM386必須自行指定可用位址。若不指定則EMM386自行規劃的UMB 空間有限。EMM386.EXE 可用的參數如下 :
NOEMS : 不模擬EMS 的功能, 但要使用UMB 。
RAM : 將記憶體模擬EMS , 且要使用UMB 。
RAM=xxxx-yyyy : 則將兩個段位址之間的記憶體留給UMB用。
size : 設定EMS 的大小, 需為16的倍數。自定值為256KB。
FRAME=xxxx : EMS 的映射頁框, 會佔用掉64KB的UMB 。
I=xxxx-yyyy : 指定段位址xxxx~yyyy可做為UMB 供LOADHI。
X=xxxx-yyyy : 避開段位址xxxx~yyyy不可做為UMB 。
EMM386自定的UMB 使用位址為C800~DFFF (共96K),若介面卡用到此位址, 則須以參數 X= 避開。
要瞭解I/O 界面卡的位址分配, 才知道那些位址可以使用或該避開。若是界面卡位址(如倚天卡版)是可調整的, 則可儘量留下最大可用的UMB 空間。
640K 到 1 Mega 的 I/O 位址分配 :
A0000 h ~ AFFFF h (64K) 彩色螢幕圖形介面
B0000 h ~ B7FFF h (32K) 單色螢幕圖文介面
B8000 h ~ BFFFF h (32K) 彩色螢幕文字介面
C0000 h ~ C7FFF h (32K) 彩色螢幕 BIOS 程式碼存放區
C8000 h ~ CFFFF h (32K) SCSI/ESDI 硬碟控制卡
D0000 h ~ DDFFF h
DE000 h ~ DFFFF h ( 8K) 倚天中文卡字型ROM 預設位址
*E0000 h ~ EFFFF h (64K) 通常是未使用, 可做UMB 。
F0000 h ~ FFFFF h (64K) 系統 ROM BIOS
顧名思義, EMM386.EXE只能用在386 或486 的PC, 若你使用286 的PC AT,就無法使用UMB 的功能了。 使用 HIMEM.SYS 和 EMM386.EXE 在原始情況下, DOS 5.0 大約佔60K 的傳統記憶體。你可以把根目錄下的CONFIG.SYS和AUTOEXEC.BAT刪除 (或用REN 更名),重新開機後,再用 MEM /C 來觀察, 則傳統記憶體的使用情況如下(註1):
> \dos\mem /c (未加config.sys和autoexec.bat的情況)
MSDOS 57184 ( 55.8K) DF60
COMMAND 4704 ( 4.6K) 1260
FREE 593328 (579.4K) 90DB0
接著如果你使用HMA,則可將約45K 的DOS 核心搬移至HMA 中, 而有約17K 的DOS 碼留在傳統記憶體中。要使用HMA,則須在CONFIG.SYS檔中加入HIMEM.SYS,和 DOS=HIGH 這兩行。作法和觀察步驟如下:
> copy con \config.sys device=\dos\himem.sys dos= high ^Z ( 按F6, Enter )
( 重新開機後 ) > \dos\mem /c
( 使用HMA 的情況 )
MSDOS 12.5K HIMEM.sys 1.2K
COMMAND.com 2.6K
FREE memory 623.6K
而且用MEM 觀察的結果, 可使用的XMS 記憶體剛好減少了64K,確實是被拿去當HMA 使用了。計算的方法, 是將全部(total) 連續延伸記憶體, 減掉可用(available) 之XMS 延伸記憶體, 則等於65536 bytes,再除以1024即為64K。 如果你使用HMA 並且在CONFIG.SYS檔中設定 BUFFERS=n 這個命令,那麼磁碟緩衝區(disk buffer) 也會自動置於HMA 中。磁碟緩衝區的設定個數, 一般是根據硬碟的容量大小來設定。大容量硬碟的BUFFERS 若太小, 則速度會變慢。以下是一些參考數據:
40 MB 以下 : BUFFERS=20
40 至 79 MB : BUFFERS=30
79 至119 MB : BUFFERS=40
120 MB 以上 : BUFFERS=50
如果HMA 不足以放下所有的磁碟緩衝區, 剩餘部分也會自動轉到傳統記憶體去儲存。事實上HMA 除了放DOS 核心程式外, 約可再放下44個BUFFERS,因此若你的硬碟容量不大, 則可設 BUFFERS=44。
接著要使用EMM386.EXE來管理UMB,則要加上 DOS=UMB 命令,且需在HIMEM.SYS 下使用。以下是使用HMA 和UMB 的CONFIG.SYS 基本內容:
device=\dos\himem.sys
dos=high umb
device=\dos\emm386.exe noems i=e000-efff
buffers=44
files=30
注意HIMEM.SYS 必須在第一行, 因為所有的XMS 功能都經由它處理。重新開機後, 由開機訊息或MEM/C 觀察, 發現增加了約160K 的UMB可以使用; 但可使用的XMS 記憶體竟然又少了245K。這是因為UMB 的位址並非連續可用的, 所以XMS 無法百分之百轉換為UMB 使用。
若你使用單色螢幕, 那麼趕快在EMM386這行後面再加個參數如下:
device=\dos\emm386.exe noems i=e000-efff i=a000-afff
重新開機後, 再以MEM 觀察, 發現傳統記憶體居然變成704K (多了64K), 連可執行的程式最大容量也增加了! 這是使用單色螢幕 386/486才有的特權。
以下再列出彩色/單色螢幕的CONFIG.SYS 設定實例 :
彩色 386/486
DEVICE=\DOS\HIMEM.SYS
DOS=HIGH UMB
DEVICE=\DOS\EMM386.EXE NOEMS I=C800-EFFF
BUFFERS=50,8
FILES=30
單色 386/486
DEVICE=\DOS\HIMEM.SYS
DOS=HIGH UMB
DEVICE=\DOS\EMM386.EXE NOEMS I=A000-AFFF I=C000-EFFF
BUFFERS=50,8
FILES=30(若只有384K延伸記憶體, 則不夠UMB 使用, 第二個I=要改成C600-EFFF)有了UMB 以後, 要執行常駐程式就可使用LOADHIGH (可簡寫為LH)命令來把常駐程式載入到UMB 了。同樣也可寫在AUTOEXEC.BAT等批次檔中。若是由CONFIG.SYS設定的驅動程式, 則把DEVICE= 改用DEVICEHIGH=來載入。但並非每個程式都可放到UMB,如 SMARTDRV 就不適合。使用UMB 的實例如下: DOS命令或用在.BAT檔中 :
LH DOSKEY
LH APPEND C:\TC\LIB;C:\JB;
CONFIG.SYS 檔的設定中 :
DEVICEHIGH=\DOS\ANSI.SYS
DEVICEHIGH=\MOUSE.SYS 2
若是UMB 客滿了, 常駐程式會自動轉置於傳統記憶體中。你可用MEM/C來觀察傳統記憶體和UMB 的使用情形。 節省記憶體的其他技巧 DOS 使用HMA 和UMB 在真實模式下作出最後的"掙扎", 但HMA和UMB增加的記憶體終究有限, 若是那天還是碰上"(傳統)記憶體不足"時要怎麼辦呢? 就只有找出下列的最後掙扎的最後技巧了。
1. 在CONFIG.SYS中加入下列命令: STACK=0,0
FCBS=1
一般應用程式很少用到STACK,設為0 可省下1K左右。而FCB 更是很落伍的軟體才用得上的。FCBS=1可省下176 bytes 。
2. 設定BUFFERS 值小一點, 例如44以下。
3. 減少FILES 值 (可開檔數目),每少一個可省下53 bytes 。
4. 檢討UMB 位址是否充分利用, 重新設定參數。或者改用QEMM386.SYS來代替 EMM386.EXE 和HIMEM.SYS 。
5. 審視所有的驅動程式和常驅程式, 沒用到的不要載入系統, 或是儘量LOADHI。如果你只在WINDOW中使用滑鼠, 可把外部的滑鼠驅動程式(如:MOUSE.COM)拿走, 因為WINDOW有自己的滑鼠驅動程式。 虛擬磁碟和磁碟快取用完了HMA 和UMB 剩下來的延伸記憶體, 對一般應用程式都用不著了, 要如何處理呢? 如果你只有384K的延伸記憶體, 也用得差不多了,就到此為止。如果你還有更多的記憶體, 就可拿來作虛擬磁碟, 或是作磁碟快取區, 來減少硬碟的讀取磨損, 並加速系統的運行。 但首先你要瞭解自己還剩下多少可使用的記憶體, 這可用MEM 來觀察, 再除以1024得到K 數。另外倚天中文3.1 版可將字型檔等載入延伸記憶體; 所以你要先執行中文系統(3.1版) 再執行MEM , 才能確定剩下多少延伸記憶體可以使用。如果還使用WINDOW等其他會使用延伸記憶體的軟體, 就需要再調整分配。 虛擬磁碟(Virtual Disk 或 RAM Disk)是以記憶體模擬磁碟, 存取檔案的速度比硬碟快, 適用於處理大量檔案或經常讀取的資料。但注意若是寫入資料到虛擬磁碟, 最後記得要轉存到硬碟上, 否則電源一關,記憶體的資料就消失了。磁碟快取(Disk Cache)是將較重要或經常讀取的硬碟資料, 存在磁碟快取區, 若有磁碟I/O 時, 就可直接從快取區拿取資料。一、虛擬磁碟工具: RAMDRIVE.SYS在 CONFIG.SYS 的設定實例:
DEVICE=\DOS\RAMDRIVE.SYS 320 512 120 /E
說明:
第一個參數: 320,使用虛擬磁碟的K 數。此值需是64(K) 的整數倍。
第二個參數: 512,每個磁區的bytes 數。512 與磁碟磁區大小一致。
第三個參數: 120,根目錄下最多可存放的檔案和子目錄個數。
參數 /E 表示使用延伸記憶體。若是 /A 則使用擴展記憶體。
不設定 /E 或 /A 則使用傳統記憶體。
二、磁碟快取工具: SMARTDRV.SYS在 CONFIG.SYS 的設定實例: DEVICE=\DOS\SMRATDRV.SYS 1024 說明:
第一個參數: 1024, 使用磁碟快取區的K 數。此值最少為128 (K)。
第二個參數: 沒設, 這是快取區的最小K 數。若使用WINDOW等會佔用延伸記憶體的軟體, 快取區會自動調成此值。另外,參數 /A 表示使用擴展記憶體,沒設則自定使用延伸記憶體。
若是你有PC-CACHE.COM或NCACHE.EXE等其他功能較強的磁碟快取程式, 可用來取代DOS 的SMARTDRV, 參數用法請參考相關的說明書。DOS 的RAMDRIVE.SYS和SMARTDRV.SYS都需配合HIMEM.SYS 使用。---------------------------------------------------------(註1) 表中MSDOS 的數值是只有一部硬碟C 的情況。若還有硬碟D,則 MSDOS 的大小是57312 Bytes,否則有可能是感染病毒。另外如果有AUTOEXEC.BAT, 則有64 Bytes的FREE區, 為環境變數區。 MEM/C 所觀察的UMB 第一項為64K ~160K 的SYSTEM, 是表示 UMB 分配給系統I/O 或ROM-BIOS使用之數量。
掛載EMM386.EXE時,碰到預期外的行為時,考慮以下列參數選項來解決:
X = a000-f7ff
如果不包括整個上層記憶體區域 (UMA) 可以解決系統問題,EMM386.EXE 可能會太積極地掃描,以及設定上層記憶體區塊 (UMBs) 在一些介面卡的最上層 ROM 或 RAM。使用任何可用的硬體文件 (包括附加元件的硬體裝置,例如視訊、 網路,以及磁碟控制器卡上的文件),來識別任何 ROM 或 RAM 出現在 [UMA 中為該裝置,並排除所有相關的區域。如果硬體文件無法使用,或者並不會提供必要的資訊,您可以使用 [Microsoft 診斷公用程式 」 (MSD) 來識別記憶體區域。
NOEMS
如果 NOEMS 參數已修正與 EMM386.EXE 問題,EMM386.EXE 可能與某些硬體 ROM 或 [UMA 中的 RAM 位址不慎衝突時嘗試建立擴充的記憶體 (EMS) 頁面框架。如果執行檢查 DOS 為主的應用程式所需 EMS,使用參數框架 = 或 M(是已定義的十六進位位址) 明確地指定 nonconflicting 區域中的 [EMS 頁面框架的位置。如果沒有應用程式需要 EMS,只是繼續使用 NOEMS 參數。
NOVCPI
NOVCPI 切換控制會停用虛擬控制項程式介面 (VCPI) 支援,並且可以用於只能在配合 NOEMS 參數中。 如果使用 NOVCPI 更正問題,應用程式可能不是與 EMM386.EXE VCPI 配置配置完全相容。請繼續使用 NOVCPI] 參數,或使用應用程式時不要載入 EMM386.EXE。
NOMOVEXBDA
某些機器使用最後的千位元組的傳統記憶體擴充的 BIOS 資料區域。預設情況下,EMM386.EXE remaps 這個記憶體區域到 UMA,而非傳統記憶體。如果這會導致未預期的系統行為,NOMOVEXBDA 參數必須用。
NOTR
EMM386.EXE 有偵測程式碼,以搜尋權杖環網路介面卡的存在。此偵測程式碼可能會造成某些電腦停止回應。NOTR 切換來停用此搜尋。
DOS 5.0 提供的記憶體管理, 指的是位址為640K以上的記憶體。如果你的電腦只有640K 的RAM, 那麼DOS 5.0 對你就沒有多大用處。一般電腦最基本配備有1 Mega的記憶體, 就有384 K 的延伸記憶體可以運用。記憶體容量愈大, 運用範圍愈廣。像WINDOW這類多工軟體, 就需要龐大的記憶體來增加其速度。
640K的傳統記憶體
640K的限制由何處來的? 這必須回顧PC和CPU 的歷史。CPU 的定址能力, 是由硬體線路所限定的。在早期APPLEⅡ 使用的6502 CPU, 它是8 位元的微處理機, 故具有8 條的資料線路。其資料處理是以位元組(Byte)為單位, 每一個Byte可表示2^8 = 256 種數字。同時它用兩個Byte的組合來指示記憶體的位址。因此它須具有16條的位址線路, 共可表達2^16 = 65536 =64K 種的位址。換句話說, 16條的位址線路的定址能力的最高限制就是64KB 。1978年Intel 公司推出16位元的8086微處理機, 以16位元的字組( Word,相當於兩個Byte) 為資料處理的單位。位址線路則增加到20條;因此必須用兩個Word來表示記憶體的位址。這兩個Word如果也採用線性對映的定址方式, 那麼共可表示: 2 ^32 = 2^2x2^10x2^10x2^10 = 4 x K x K x K = 4G 種的位址!這在當時看來是軟硬體皆不可能達成的數字。更何況位址線又沒有32條,只有20條而已, 就是說實際定址能力的最高限制是2^20 Bytes = 1MB。那時的RAM 也很昂貴, 所以認為1MB (是64KB 的16倍) 是夠大的了。
因此8086採取了重疊對映的定址方式 (悲劇的開始!)。由兩個Word以XXXX:YYYY 的方式來組成一個20位元的線性位址, 前者為節區段位址(Segment),後面稱偏移段位址(Offset)。
公式如下:Address = Segment * 16 + Offset
格式:Segment:offset =>(段位址):(偏移位址) =>1 2 3 4 : 2 3 4 5
1 2 3 4 0
+2 3 4 5
(真實記憶體位址) --------------
1 4 6 8 5 h
以上的記憶體位址是16進位數字, 在數字後面附加小寫h 來表示。例如: 640K (10進位) = A0000 h = A000:0000 等到1982年, 藍色巨人IBM 推出最早型的IBM PC XT,以Intel 8088微處理機作為CPU,8088與8086都只有20條位址線(A0~A19) 。IBM 對可定址的1MB 記憶體位址做個規劃, 其中最前面的640K RAM供DOS 與應用程式使用, 這塊區域叫主記憶體(Base Memory) 或傳統記憶體。640K到1MB 的記憶體區域保留給外加擴充的界面卡和BIOS使用, 這塊區域叫上層記憶體 (Upper Memory),一般應用程式不可輕易動用。這也就是DOS和一般應用程式最多只能控制640K的原因。
1983年Intel 推出了80286, IBM立刻選用為最新的CPU,於1984年底推出IBM PC AT(AT是Advanced Technology 先進技術之意) 。80286 是真正的16位元微處理機(CPU內部與I/O 均以16位元處理),運作速度更快。它有24條位址線, 故最多可存取2^24 = 16MB 的記憶體。
事實上80286 採用了兩種定址模式:一、真實模式 (Real Mode)在此模式下,286使用和8086/8088 相同的重疊對映的定址方式。這是為了讓原有的DOS 和應用程式能在PC AT 上相容使用。因此, 在真實模式下, 也只能控制1MB 記憶體而已。二、虛擬保護模式 (Virtual Protected Mode)在保護模式下, 才能隨意使用1MB 以上的記憶體。後來陸續推出32位元的80386和80486 (皆有32條位址線),又提供了功能更強的保護模式。但是也都保留了真實模式, 以滿足往前的相容。MS-DOS改版至今, 一直是在真實模式下運作。對於在286/386/486超過1024K 的記憶體, 只能拿來當虛擬磁碟機, 或硬碟快取程式(Disk cache), 或者使用一些其他的驅動程式 (如EMM或XMM) 來支援, 而不能像在傳統記憶體一樣方便的使用。 擴展記憶體和延伸記憶體早在XT時代, 一些大型軟體就有記憶體不足的困擾了。因此, Lotus/Intel/Microsoft三家公司共同制定了一個擴展記憶體規格(Expanded Memory Spec.;EMS),採用記憶庫切換(bank swapping) 的方式來指定位置段落。擴展記憶體規格(EMS) 包含了硬體的EMS 擴充界面卡, 和軟體的管理程式(Expanded Memory Manager ;EMM)。這種EMS 記憶體就是擴展記憶體 (Expanded Memory) 。
隨著PC AT 的普及, 程式可透過保護模式存取位址為1MB 以上的記憶體。這些位址為1MB 以上的記憶體就稱為延伸記憶體( Extended Memory) 。為了避免各程式取用的延伸記憶體的區域相衝突, Mircrosoft、Intel、Lotus等公司制定了一個延伸記憶體規格(Extended Memory Spec. ;XMS), 規定了高記憶區、上層記憶體與延伸記憶體的存取標準。一般的程式只要呼叫管理程式(eXtended Memory Manager ;XMM), 就能有效運用XMS 的資源。像MS-DOS 5.0的HIMEM.SYS 就是符合XMS 標準的管理程式。
Expanded(擴展)表示向橫的方向擴展, Extended則是縱向的延伸。EMS 和XMS 不同的地方是: EMS 是XT時代發展出的規格; 擴展記憶體、EMS 卡是隨著EMS 發表的, 它的重點是在1024K 的定址範圍內使用更多的記憶體, 實際的定址限制仍是1024K。
XMS 則是在有了延伸記憶體之後才訂定的規格, 用來管理640K以外的記憶體。延伸記憶體可用軟體方式模擬成EMS 標準, 讓只支援EMS 的較早期程式也能夠使用。如果你要擴充記憶體容量, 且你的主機板上仍有空的記憶體插槽,就可直接買RAM 來插, 即增加延伸記憶體, 就可做為XMS 或EMS 使用,也比EMS 卡便宜。若您的主機板上已無空的記憶體插槽, 那只好買EMS卡來插在擴充槽上了。有些EMS 卡上有開關, 可將卡上的記憶體調成延伸記憶體; 否則就只能當做擴展記憶體了。
EMS 使用記憶庫切換的方法, 在有限位址內使用更多的記憶體, 事實上只解決資料的問題, 要執行程式仍然很麻煩。這方法和SuperVGA的切頁方式類似, 若用SuperVGA則較容易理解 "切頁對映" 的觀念。PC分配給彩色螢幕的視訊對映位址只有64K (A0000h ~ AFFFFh),而SuperVGA若要顯示1024x768x256色的模式, 則需要768K 的記憶體(所以SuperVGA卡要有1MB RAM), 64K 的位址如何夠用呢? SuperVGA就把這1MB RAM 分成16個64K 等分,CPU每次可存取其中的64K,而用一個暫存器來選擇切換。
高記憶區 HMA 與 上層記憶區塊 UMB 雖然一般程式在真實模式下只能使用640K, 但DOS 5.0 提供了HMA和UMB 記憶區的使用, 在真實模式下突破了640K的限制。約64K 的高記憶區 ( HMA, High Memory Area )真實模式下的最大位址可達FFFF:FFFF = 10FFEF h的位址, 這已超過真實模式的1 Mega上限。所以多出來的100000h 到10FFEFh 就會捲繞(wrapping)重新對映到位址0 ~FFEFh 的地方。對286 以上的CPU,如果將位址線A20 致能(enable), 則不會發生捲繞, 多出來的這64K-16bytes就是HMA 。一般說HMA 有64K,其實是64K - 16 bytes 。上層記憶區塊 ( UMB, Upper Memory Block )PC把位址為640K到1MB (即A0000 h ~FFFFF h) 的上層記憶體, 規劃給界面卡和BIOS使用。這部分的ROM 除了系統BIOS是在主機母板之外, 其他的ROM (或RAM) 則是在使用該位址的界面卡上。
通常我們都只用到上層記憶體的位址的一部分而已, 其他可用的位址就浪費掉了。使用DOS 5.0 的EMM386.EXE, 可以將這些沒有使用到的上層記憶體位址, 改成對映到延伸記憶體上, 就叫做UMB 。這樣你在真實模式下, 就又多出一部分可使用的位址了。
這些多出來的UMB 記憶體, 通常用來存放各種佔記憶體的驅動程式和常駐程式, 儘量空出傳統記憶體空間來執行大型程式。
UMB 依據個人週邊配備和設定的不同, 約可多出60K~200K 左右的可使用位址。EMM386.EXE就是管理UMB 的工具。QEMM386 (Quarterdeck公司的軟體) 功能比EMM386強大,不用加參數即可規劃出最大的可用UMB, 因此很多人使用。但你還是要瞭解EMM386, 以便可隨時更替, 因為EMM386的功能較穩定。
使用EMM386必須自行指定可用位址。若不指定則EMM386自行規劃的UMB 空間有限。EMM386.EXE 可用的參數如下 :
NOEMS : 不模擬EMS 的功能, 但要使用UMB 。
RAM : 將記憶體模擬EMS , 且要使用UMB 。
RAM=xxxx-yyyy : 則將兩個段位址之間的記憶體留給UMB用。
size : 設定EMS 的大小, 需為16的倍數。自定值為256KB。
FRAME=xxxx : EMS 的映射頁框, 會佔用掉64KB的UMB 。
I=xxxx-yyyy : 指定段位址xxxx~yyyy可做為UMB 供LOADHI。
X=xxxx-yyyy : 避開段位址xxxx~yyyy不可做為UMB 。
EMM386自定的UMB 使用位址為C800~DFFF (共96K),若介面卡用到此位址, 則須以參數 X= 避開。
要瞭解I/O 界面卡的位址分配, 才知道那些位址可以使用或該避開。若是界面卡位址(如倚天卡版)是可調整的, 則可儘量留下最大可用的UMB 空間。
640K 到 1 Mega 的 I/O 位址分配 :
A0000 h ~ AFFFF h (64K) 彩色螢幕圖形介面
B0000 h ~ B7FFF h (32K) 單色螢幕圖文介面
B8000 h ~ BFFFF h (32K) 彩色螢幕文字介面
C0000 h ~ C7FFF h (32K) 彩色螢幕 BIOS 程式碼存放區
C8000 h ~ CFFFF h (32K) SCSI/ESDI 硬碟控制卡
D0000 h ~ DDFFF h
DE000 h ~ DFFFF h ( 8K) 倚天中文卡字型ROM 預設位址
*E0000 h ~ EFFFF h (64K) 通常是未使用, 可做UMB 。
F0000 h ~ FFFFF h (64K) 系統 ROM BIOS
顧名思義, EMM386.EXE只能用在386 或486 的PC, 若你使用286 的PC AT,就無法使用UMB 的功能了。 使用 HIMEM.SYS 和 EMM386.EXE 在原始情況下, DOS 5.0 大約佔60K 的傳統記憶體。你可以把根目錄下的CONFIG.SYS和AUTOEXEC.BAT刪除 (或用REN 更名),重新開機後,再用 MEM /C 來觀察, 則傳統記憶體的使用情況如下(註1):
> \dos\mem /c (未加config.sys和autoexec.bat的情況)
MSDOS 57184 ( 55.8K) DF60
COMMAND 4704 ( 4.6K) 1260
FREE 593328 (579.4K) 90DB0
接著如果你使用HMA,則可將約45K 的DOS 核心搬移至HMA 中, 而有約17K 的DOS 碼留在傳統記憶體中。要使用HMA,則須在CONFIG.SYS檔中加入HIMEM.SYS,和 DOS=HIGH 這兩行。作法和觀察步驟如下:
> copy con \config.sys device=\dos\himem.sys dos= high ^Z ( 按F6, Enter )
( 重新開機後 ) > \dos\mem /c
( 使用HMA 的情況 )
MSDOS 12.5K HIMEM.sys 1.2K
COMMAND.com 2.6K
FREE memory 623.6K
而且用MEM 觀察的結果, 可使用的XMS 記憶體剛好減少了64K,確實是被拿去當HMA 使用了。計算的方法, 是將全部(total) 連續延伸記憶體, 減掉可用(available) 之XMS 延伸記憶體, 則等於65536 bytes,再除以1024即為64K。 如果你使用HMA 並且在CONFIG.SYS檔中設定 BUFFERS=n 這個命令,那麼磁碟緩衝區(disk buffer) 也會自動置於HMA 中。磁碟緩衝區的設定個數, 一般是根據硬碟的容量大小來設定。大容量硬碟的BUFFERS 若太小, 則速度會變慢。以下是一些參考數據:
40 MB 以下 : BUFFERS=20
40 至 79 MB : BUFFERS=30
79 至119 MB : BUFFERS=40
120 MB 以上 : BUFFERS=50
如果HMA 不足以放下所有的磁碟緩衝區, 剩餘部分也會自動轉到傳統記憶體去儲存。事實上HMA 除了放DOS 核心程式外, 約可再放下44個BUFFERS,因此若你的硬碟容量不大, 則可設 BUFFERS=44。
接著要使用EMM386.EXE來管理UMB,則要加上 DOS=UMB 命令,且需在HIMEM.SYS 下使用。以下是使用HMA 和UMB 的CONFIG.SYS 基本內容:
device=\dos\himem.sys
dos=high umb
device=\dos\emm386.exe noems i=e000-efff
buffers=44
files=30
注意HIMEM.SYS 必須在第一行, 因為所有的XMS 功能都經由它處理。重新開機後, 由開機訊息或MEM/C 觀察, 發現增加了約160K 的UMB可以使用; 但可使用的XMS 記憶體竟然又少了245K。這是因為UMB 的位址並非連續可用的, 所以XMS 無法百分之百轉換為UMB 使用。
若你使用單色螢幕, 那麼趕快在EMM386這行後面再加個參數如下:
device=\dos\emm386.exe noems i=e000-efff i=a000-afff
重新開機後, 再以MEM 觀察, 發現傳統記憶體居然變成704K (多了64K), 連可執行的程式最大容量也增加了! 這是使用單色螢幕 386/486才有的特權。
以下再列出彩色/單色螢幕的CONFIG.SYS 設定實例 :
彩色 386/486
DEVICE=\DOS\HIMEM.SYS
DOS=HIGH UMB
DEVICE=\DOS\EMM386.EXE NOEMS I=C800-EFFF
BUFFERS=50,8
FILES=30
單色 386/486
DEVICE=\DOS\HIMEM.SYS
DOS=HIGH UMB
DEVICE=\DOS\EMM386.EXE NOEMS I=A000-AFFF I=C000-EFFF
BUFFERS=50,8
FILES=30(若只有384K延伸記憶體, 則不夠UMB 使用, 第二個I=要改成C600-EFFF)有了UMB 以後, 要執行常駐程式就可使用LOADHIGH (可簡寫為LH)命令來把常駐程式載入到UMB 了。同樣也可寫在AUTOEXEC.BAT等批次檔中。若是由CONFIG.SYS設定的驅動程式, 則把DEVICE= 改用DEVICEHIGH=來載入。但並非每個程式都可放到UMB,如 SMARTDRV 就不適合。使用UMB 的實例如下: DOS命令或用在.BAT檔中 :
LH DOSKEY
LH APPEND C:\TC\LIB;C:\JB;
CONFIG.SYS 檔的設定中 :
DEVICEHIGH=\DOS\ANSI.SYS
DEVICEHIGH=\MOUSE.SYS 2
若是UMB 客滿了, 常駐程式會自動轉置於傳統記憶體中。你可用MEM/C來觀察傳統記憶體和UMB 的使用情形。 節省記憶體的其他技巧 DOS 使用HMA 和UMB 在真實模式下作出最後的"掙扎", 但HMA和UMB增加的記憶體終究有限, 若是那天還是碰上"(傳統)記憶體不足"時要怎麼辦呢? 就只有找出下列的最後掙扎的最後技巧了。
1. 在CONFIG.SYS中加入下列命令: STACK=0,0
FCBS=1
一般應用程式很少用到STACK,設為0 可省下1K左右。而FCB 更是很落伍的軟體才用得上的。FCBS=1可省下176 bytes 。
2. 設定BUFFERS 值小一點, 例如44以下。
3. 減少FILES 值 (可開檔數目),每少一個可省下53 bytes 。
4. 檢討UMB 位址是否充分利用, 重新設定參數。或者改用QEMM386.SYS來代替 EMM386.EXE 和HIMEM.SYS 。
5. 審視所有的驅動程式和常驅程式, 沒用到的不要載入系統, 或是儘量LOADHI。如果你只在WINDOW中使用滑鼠, 可把外部的滑鼠驅動程式(如:MOUSE.COM)拿走, 因為WINDOW有自己的滑鼠驅動程式。 虛擬磁碟和磁碟快取用完了HMA 和UMB 剩下來的延伸記憶體, 對一般應用程式都用不著了, 要如何處理呢? 如果你只有384K的延伸記憶體, 也用得差不多了,就到此為止。如果你還有更多的記憶體, 就可拿來作虛擬磁碟, 或是作磁碟快取區, 來減少硬碟的讀取磨損, 並加速系統的運行。 但首先你要瞭解自己還剩下多少可使用的記憶體, 這可用MEM 來觀察, 再除以1024得到K 數。另外倚天中文3.1 版可將字型檔等載入延伸記憶體; 所以你要先執行中文系統(3.1版) 再執行MEM , 才能確定剩下多少延伸記憶體可以使用。如果還使用WINDOW等其他會使用延伸記憶體的軟體, 就需要再調整分配。 虛擬磁碟(Virtual Disk 或 RAM Disk)是以記憶體模擬磁碟, 存取檔案的速度比硬碟快, 適用於處理大量檔案或經常讀取的資料。但注意若是寫入資料到虛擬磁碟, 最後記得要轉存到硬碟上, 否則電源一關,記憶體的資料就消失了。磁碟快取(Disk Cache)是將較重要或經常讀取的硬碟資料, 存在磁碟快取區, 若有磁碟I/O 時, 就可直接從快取區拿取資料。一、虛擬磁碟工具: RAMDRIVE.SYS在 CONFIG.SYS 的設定實例:
DEVICE=\DOS\RAMDRIVE.SYS 320 512 120 /E
說明:
第一個參數: 320,使用虛擬磁碟的K 數。此值需是64(K) 的整數倍。
第二個參數: 512,每個磁區的bytes 數。512 與磁碟磁區大小一致。
第三個參數: 120,根目錄下最多可存放的檔案和子目錄個數。
參數 /E 表示使用延伸記憶體。若是 /A 則使用擴展記憶體。
不設定 /E 或 /A 則使用傳統記憶體。
二、磁碟快取工具: SMARTDRV.SYS在 CONFIG.SYS 的設定實例: DEVICE=\DOS\SMRATDRV.SYS 1024 說明:
第一個參數: 1024, 使用磁碟快取區的K 數。此值最少為128 (K)。
第二個參數: 沒設, 這是快取區的最小K 數。若使用WINDOW等會佔用延伸記憶體的軟體, 快取區會自動調成此值。另外,參數 /A 表示使用擴展記憶體,沒設則自定使用延伸記憶體。
若是你有PC-CACHE.COM或NCACHE.EXE等其他功能較強的磁碟快取程式, 可用來取代DOS 的SMARTDRV, 參數用法請參考相關的說明書。DOS 的RAMDRIVE.SYS和SMARTDRV.SYS都需配合HIMEM.SYS 使用。---------------------------------------------------------(註1) 表中MSDOS 的數值是只有一部硬碟C 的情況。若還有硬碟D,則 MSDOS 的大小是57312 Bytes,否則有可能是感染病毒。另外如果有AUTOEXEC.BAT, 則有64 Bytes的FREE區, 為環境變數區。 MEM/C 所觀察的UMB 第一項為64K ~160K 的SYSTEM, 是表示 UMB 分配給系統I/O 或ROM-BIOS使用之數量。
掛載EMM386.EXE時,碰到預期外的行為時,考慮以下列參數選項來解決:
X = a000-f7ff
如果不包括整個上層記憶體區域 (UMA) 可以解決系統問題,EMM386.EXE 可能會太積極地掃描,以及設定上層記憶體區塊 (UMBs) 在一些介面卡的最上層 ROM 或 RAM。使用任何可用的硬體文件 (包括附加元件的硬體裝置,例如視訊、 網路,以及磁碟控制器卡上的文件),來識別任何 ROM 或 RAM 出現在 [UMA 中為該裝置,並排除所有相關的區域。如果硬體文件無法使用,或者並不會提供必要的資訊,您可以使用 [Microsoft 診斷公用程式 」 (MSD) 來識別記憶體區域。
NOEMS
如果 NOEMS 參數已修正與 EMM386.EXE 問題,EMM386.EXE 可能與某些硬體 ROM 或 [UMA 中的 RAM 位址不慎衝突時嘗試建立擴充的記憶體 (EMS) 頁面框架。如果執行檢查 DOS 為主的應用程式所需 EMS,使用參數框架 = 或 M
NOVCPI
NOVCPI 切換控制會停用虛擬控制項程式介面 (VCPI) 支援,並且可以用於只能在配合 NOEMS 參數中。 如果使用 NOVCPI 更正問題,應用程式可能不是與 EMM386.EXE VCPI 配置配置完全相容。請繼續使用 NOVCPI] 參數,或使用應用程式時不要載入 EMM386.EXE。
NOMOVEXBDA
某些機器使用最後的千位元組的傳統記憶體擴充的 BIOS 資料區域。預設情況下,EMM386.EXE remaps 這個記憶體區域到 UMA,而非傳統記憶體。如果這會導致未預期的系統行為,NOMOVEXBDA 參數必須用。
NOTR
EMM386.EXE 有偵測程式碼,以搜尋權杖環網路介面卡的存在。此偵測程式碼可能會造成某些電腦停止回應。NOTR 切換來停用此搜尋。
himem.sys及emm386說明

himem.sys及emm386說明轉載自http://club.it.sohu.com/r-os-239366-0-13-900.html
DOS的環境下,系統中存在以下四種記憶體:
常規記憶體(Conventional Memory)
高端記憶體(Upper Memory)
延伸記憶體(Expanded Memory) EMS
擴展記憶體(Extended Memory) XMS
DOS在實模式下,能直接定址的範圍是1MB。而這1MB分為640KB的常規記憶體和384KB的高端記憶體,加在一起就是1024KB也就是1MB。因為DOS使用16位段基址:偏移量格式(segment:offset),只能使用低端的640KB,這就是有名的640KB限制。其中最低端的1KB,即00000H~003FFH存放的是中斷(IRQ)向量表;接下來是256B(0FFH)的BIOS資料區;DOS及應用程式使用00500H~9FFFFH。這在開始使用DOS的20世紀80年代是完全能夠滿足要求的,因為當時PC上安裝的實體記憶體容量也是640KB,甚至更少。(前面地址中的H代表16進制)系統硬體使用的記憶體位於位址區域的高端,範圍是A0000H~FFFFFH,共384KB。其中有用於顯示的視頻緩衝區和BIOS程式空間,例如顯卡,網卡和主板BIOS。
地址FFFF0H在PC中有特別的用途。
電腦在加電啟動時,CPU中的CS=F000H,IP=FFF0H,即從位址FFFF0H處開始執行,這個區域屬於系統BIOS。F000:FFF0=EA5BE000F0(是JMP F000:E05B指令的十六進位表示),它立即跳轉到BIOS的初始化程式,開始系統自檢。(這段跟DOS沒有關係,只是查資料時看到了,就也寫上了。是想讓大家知道,在按下主機電源開關後,CPU都做了些什麼,為什麼BIOS開始工作,自檢硬體設備)
最後我附了一張圖,本來想自己畫的,可一搜發現已經有人畫好了,並且畫的肯定比我好,我就用人家的圖了,一看這個,肯定就清楚多了,比文字怎麼寫的都強。
上面說的延伸記憶體是一種硬體,那個年代的主板專門預留了擴展槽,可以插上,我是沒見過。擴展記憶體就是記憶體條上大於1M的部分,通過DOS下的一些驅動可以將XMS的一部分虛擬成EMS,以滿足一些為EMS開發的程式的需要。
中間有一段叫高端記憶體,指位於常規記憶體之上的384K記憶體。程式一般不能使用這個記憶體區域,但是EMM386.exe可以啟動高端記憶體的一部分,並且它允許用戶將某些設備驅動程式和用戶程式用Devicehigh或LH(即loadhigh)裝入高端記憶體。dos=high,umb也是把DOS的一部分裝到高端記憶體裏。這裏的umb是高端記憶體塊(Upper Memory Block)的縮寫。(以後我會專門寫config.sys的部分)
DOS的程式,主要還是要使用常規記憶體的,如我刷HP筆記本的BIOS的時候,連點Shift進入最小的DOS模式也就是為了節省640K這部分的空間,以便讓HP的刷寫程式有足夠的空間運行,不然刷寫程式就要報錯,就算XMS再大也沒用。
還有一個叫DOS4GW.EXE的程式,在DOS玩過一些大一些的遊戲如仙劍,紅警等,在啟動的時候,有時候能看到有個DOS4GW一閃而過,它可以使用CPU直接進入保護模式,直接訪問XMS,不過這時就已經脫離了DOS狀態。後來的Windows 3.x,95,98也都運行在保護模式下的,但都需要DOS帶一下。
有些東西要看一下計算機組成原理或彙編之類的書才能理解,尤其是記憶體的定址與CPU的寄存器(上面提到的CS,IP等)。提到了DOS的記憶體管理,從前文的圖中,大家也看到了EMM386.EXE與HIMEM.SYS,這是實際管理記憶體的模組。
EMM386.EXE從名稱上可以很真接的看出,這個是要在386以及之後的CPU上才可以使用的,它的作用是利用XMS創建出EMS,以前的DOS也有N多版本,有的叫EMM386.SYS有的叫EMM386.EXE,在我使用過的DOS我只見到過EMM386.EXE。像其他的擴展記憶體管理一樣EMM386使處理器虛擬8086的模式。而在386增強模式中,視窗會話期間會臨時關閉,同時在視窗保護模式中內核會接管它的角色。最終的作用是在UMA中,EMM386.EXE會把記憶體映射成未使用的塊。允許設備驅動和TSRs(我也不知道是什麼東西)被載入到UMA中,而保留那可憐的640K的常規記憶體。
HIMEM.SYS也是一個DOS設備驅動,他允許DOS程式把資料存到XMS中去。HIMEM.SYS實際上是非常重要的,後來的多種Windows作業系統(本質上底層是依賴於DOS)都需要先載入HIMEM.SYS之後才能正常運行。
從MSDOS 5.0起,HIMEM.SYS被用來把DOS內核的部分代碼載入到HMA中,目的同樣是為了節省那640K的常規記憶體。在config.sys用dos=high設置,config.sys的詳細資訊,後文會有涉及。
HIMEM.SYS提供了一種訪問超過1M實體記憶體的方法,而這正是windows 9x/me作業系統載入圖型化介面所必需的,看前面的圖很清楚,EMM386.EXE的管轄範圍是640K向上到1M之間這部分共384K被稱作上位記憶體UMA的區域。而HIMEM.SYS管轄的是1M再向上的部分,而從1M開始有一小段叫高位記憶體HMA,專門用來放一部分DOS內核。
常規記憶體(Conventional Memory)
高端記憶體(Upper Memory)
延伸記憶體(Expanded Memory) EMS
擴展記憶體(Extended Memory) XMS
DOS在實模式下,能直接定址的範圍是1MB。而這1MB分為640KB的常規記憶體和384KB的高端記憶體,加在一起就是1024KB也就是1MB。因為DOS使用16位段基址:偏移量格式(segment:offset),只能使用低端的640KB,這就是有名的640KB限制。其中最低端的1KB,即00000H~003FFH存放的是中斷(IRQ)向量表;接下來是256B(0FFH)的BIOS資料區;DOS及應用程式使用00500H~9FFFFH。這在開始使用DOS的20世紀80年代是完全能夠滿足要求的,因為當時PC上安裝的實體記憶體容量也是640KB,甚至更少。(前面地址中的H代表16進制)系統硬體使用的記憶體位於位址區域的高端,範圍是A0000H~FFFFFH,共384KB。其中有用於顯示的視頻緩衝區和BIOS程式空間,例如顯卡,網卡和主板BIOS。
地址FFFF0H在PC中有特別的用途。
電腦在加電啟動時,CPU中的CS=F000H,IP=FFF0H,即從位址FFFF0H處開始執行,這個區域屬於系統BIOS。F000:FFF0=EA5BE000F0(是JMP F000:E05B指令的十六進位表示),它立即跳轉到BIOS的初始化程式,開始系統自檢。(這段跟DOS沒有關係,只是查資料時看到了,就也寫上了。是想讓大家知道,在按下主機電源開關後,CPU都做了些什麼,為什麼BIOS開始工作,自檢硬體設備)
最後我附了一張圖,本來想自己畫的,可一搜發現已經有人畫好了,並且畫的肯定比我好,我就用人家的圖了,一看這個,肯定就清楚多了,比文字怎麼寫的都強。
上面說的延伸記憶體是一種硬體,那個年代的主板專門預留了擴展槽,可以插上,我是沒見過。擴展記憶體就是記憶體條上大於1M的部分,通過DOS下的一些驅動可以將XMS的一部分虛擬成EMS,以滿足一些為EMS開發的程式的需要。
中間有一段叫高端記憶體,指位於常規記憶體之上的384K記憶體。程式一般不能使用這個記憶體區域,但是EMM386.exe可以啟動高端記憶體的一部分,並且它允許用戶將某些設備驅動程式和用戶程式用Devicehigh或LH(即loadhigh)裝入高端記憶體。dos=high,umb也是把DOS的一部分裝到高端記憶體裏。這裏的umb是高端記憶體塊(Upper Memory Block)的縮寫。(以後我會專門寫config.sys的部分)
DOS的程式,主要還是要使用常規記憶體的,如我刷HP筆記本的BIOS的時候,連點Shift進入最小的DOS模式也就是為了節省640K這部分的空間,以便讓HP的刷寫程式有足夠的空間運行,不然刷寫程式就要報錯,就算XMS再大也沒用。
還有一個叫DOS4GW.EXE的程式,在DOS玩過一些大一些的遊戲如仙劍,紅警等,在啟動的時候,有時候能看到有個DOS4GW一閃而過,它可以使用CPU直接進入保護模式,直接訪問XMS,不過這時就已經脫離了DOS狀態。後來的Windows 3.x,95,98也都運行在保護模式下的,但都需要DOS帶一下。
有些東西要看一下計算機組成原理或彙編之類的書才能理解,尤其是記憶體的定址與CPU的寄存器(上面提到的CS,IP等)。提到了DOS的記憶體管理,從前文的圖中,大家也看到了EMM386.EXE與HIMEM.SYS,這是實際管理記憶體的模組。
EMM386.EXE從名稱上可以很真接的看出,這個是要在386以及之後的CPU上才可以使用的,它的作用是利用XMS創建出EMS,以前的DOS也有N多版本,有的叫EMM386.SYS有的叫EMM386.EXE,在我使用過的DOS我只見到過EMM386.EXE。像其他的擴展記憶體管理一樣EMM386使處理器虛擬8086的模式。而在386增強模式中,視窗會話期間會臨時關閉,同時在視窗保護模式中內核會接管它的角色。最終的作用是在UMA中,EMM386.EXE會把記憶體映射成未使用的塊。允許設備驅動和TSRs(我也不知道是什麼東西)被載入到UMA中,而保留那可憐的640K的常規記憶體。
HIMEM.SYS也是一個DOS設備驅動,他允許DOS程式把資料存到XMS中去。HIMEM.SYS實際上是非常重要的,後來的多種Windows作業系統(本質上底層是依賴於DOS)都需要先載入HIMEM.SYS之後才能正常運行。
從MSDOS 5.0起,HIMEM.SYS被用來把DOS內核的部分代碼載入到HMA中,目的同樣是為了節省那640K的常規記憶體。在config.sys用dos=high設置,config.sys的詳細資訊,後文會有涉及。
HIMEM.SYS提供了一種訪問超過1M實體記憶體的方法,而這正是windows 9x/me作業系統載入圖型化介面所必需的,看前面的圖很清楚,EMM386.EXE的管轄範圍是640K向上到1M之間這部分共384K被稱作上位記憶體UMA的區域。而HIMEM.SYS管轄的是1M再向上的部分,而從1M開始有一小段叫高位記憶體HMA,專門用來放一部分DOS內核。
2010年4月12日 星期一
Novell Netware3.12安裝在VMware Workstation 6.5(中)
 圖一
圖一 圖二
圖二 圖三
圖三 圖四
圖四要安裝SYS卷及public公用程式的安裝比較簡單所以我只把圖show出來。流程大致上是1.check HD partition 2.create SYS volume產生系統卷 3.copy System and Public Files。設定過程使用預設值便可。首先進入system console後輸入load install。
2010年4月11日 星期日
Novell Netware3.12安裝在VMware Workstation 6.5(下)
 圖DONE
圖DONE 圖一
圖一 圖二
圖二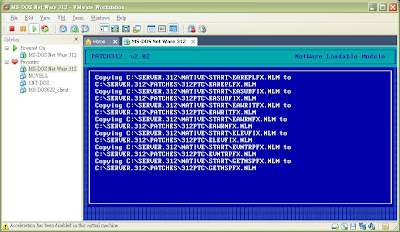 圖三
圖三 圖四
圖四 圖五
圖五  圖六
圖六 圖七
圖七 圖八
圖八 圖九
圖九 圖十
圖十 圖十一
圖十一 圖十二
圖十二 圖十三
圖十三安裝312ptd patch
將312ptd.exe解壓縮後:312PTD.TXT及312PTD(directory),我列出312ptd.txt最重要的部分如下:注意312PTD資料夾包括PATCH312.NLM及NATIVE資料夾
INSTALLATION INSTRUCTIONS
1. Extract the file on the SYS Volume.將PATCH312.NLM及NATIVE資料夾存放到C:\server.312
2. At the server console prompt type "LOAD PATCH312".
3. At the prompt select "Copy OS Patches to Server".
4. At the prompt to Enter Patch Source Path type SYS:312PTC. (Or directorypath where the file was extracted.)
5. Select EXIT when the file copy is finished.
6. DOWN and EXIT the server and restart.
實際安裝Patch的畫面如上圖一~圖五;另外會出現圖四是正常,若在安裝完系統卷後有去create autoexec.ncf就不會有這個問題。但以後我們再來新增autoexec.ncf也沒關係。
安裝odi33g patch
將odi33g.exe解壓縮後:有ODI33G.TXT、ODIKIT.IPS、PI_ICMD.NLM、PI_IOCON.NLM、PI_IOMKD.NLM、SERVER資料夾、RPL資料夾。以下列出ODI33G.TXT的重要安裝資訊:
Installation Instructions on 3.1X/3.2 versions of NetWare:
1) Extract ODI33G to a Network drive on the file server. If you are using diskettes to install ODI33G, you will need to format two diskettes. Labelone diskette "SERVER" and the other "RPL" using the dos label command. Copy all of the files (including subdirectories and files) in the Serverdirectory of ODI33G to the diskette labeled "SERVER". Copy all of the files(including subdirectories and files) in the RPL directory of ODI33G to thediskette labeled"RPL".
這段話的意思是要使用兩塊磁片分別存放ODI33G.exe所解壓縮出來的資料,其中一個磁碟片標籤貼為"server"另一個為"RPL"。然而我們已經有硬碟了不要這麼搞就全部複製到c:\server.312;雖然我知道RPL資料夾現在用不到,因為這個資料夾存放的是和boot from network有關的資訊。有一點特別重要就是在這個server資料夾其絕對路徑是c:\server.312\server\33SPEC中將我們的AMD pcnet網卡drivers(pcntnw.lan及pcntnw.ldi)也存放到這裡來。
2) Load Install at the file server.在system console輸入load install命令
3) Select "Product Options".
4) Press "Ins".按下鑑盤上的insert按鍵
5) Enter the path to the location of the "SERVER" directory where ODI33G was extracted..ie SYS:\SERVER. 在此我輸入的路徑是C:\SERVER.312\SERVER
6) Select "Install Product".
7) Press "Enter" and select "Yes" to start the installation.
安裝過程如圖六 ~圖十三。以上兩個patches已安裝完成。
接下來已經接近尾聲,只剩下把autoexec.ncf設定完成就可以開始來測試連線了。AUTOEXEC.NCF:
FILE SERVER NAME BENSON
IPX INTERNAL NET 80862240
MOUNT ALL
LOAD C:\SERVER.312\NBI31X
LOAD C:\SERVER.312\MSM31X
LOAD C:\SERVER.312\ETHERTSM
LOAD PCNTNW PORT=2000 INT=A SLOT=10001 FRAME=ETHERNET_802.3
BIND IPX TO PCNTNW NET=540321
LOAD C:\SERVER.312\NW4-IDLE ;此行可以使整個CPU使用率下降
LOAD MONITOR
LOAD MONITOR
搞定,可參考連線畫面如圖DONE.顯示有兩個client以supervisor身分登入.
2010年4月7日 星期三
NetWare 3.12的安裝配置
NetWare 3.12的安裝配置
轉載於http://www.xy1z.cn/Article/ShowArticle.asp?ArticleID=865
一、網卡配置:
為方便安裝,各工作站及伺服器網卡都採用相同配置:NE2000網卡、I/O位址:300H、中斷:3
二、伺服器的安裝:
為伺服器的硬碟上用DOS的FDISK命令分一個不小於50M的DOS分區,其餘硬碟空間不分區。在DOS分區裝好DOS作業系統,如果使用DOS5.0以上的DOS,去掉環境設置中的擴展和延伸記憶體配置。在C盤根目錄用DOS的MD命令生成SERVER.312目錄,並在該目錄下依次生成子目錄UNICODE,SYSTEM-1,SYSTEM-2,SYSTEM-3,SYSTEM-4,SYSTEM-5,SYSTEM-6,SYSTEM-7和SYSTEM-8,並用DOS的XCOPY命令把NetWare 3.12相應的盤拷貝到對應的子目錄下。用DOS的COPY命令拷貝SYSTEM-1盤上的INSTALL.NLM,ISADISK.DSK,SERVER.EXE,KEYB.NLM文件和SYSTEM-3盤上的ETHERTSM.NLM,MSM31X.NLM,NE2000.LAN文件到SERVER.312目錄。
用DOS的CD命令進入SERVER.312目錄,鍵入:SERVER↓ 開始安裝。按螢幕指示鍵入檔伺服器名和網路號。
File server name: FS↓
IPX internal network number:123↓
裝入硬碟卡驅動程式,將不同的硬碟卡需裝入不同的驅動程式,其尾碼名為.DSK,一般的AT-BUS的硬碟卡裝入ISADISK.DSK,中斷及I/O Port值都取缺省值。
FS:load isadisk↓
I/O port: 1FO↓
Interupt number: E↓
裝入網卡驅動程式,不同的網卡需裝入不同的驅動程式,在此用NE2000網卡。
FS:load ne2000↓
I/O port:300↓
Interrupt number:3↓
連接通信協定,並給定網路電纜號:
FS:bind ipx to ne2000↓
NETWORK NUMBER: 1234↓
裝入安裝網路作業系統的安裝程式:
FS:load install↓
依次選擇Disk Options,Partition Tables,Create NetWare Partition項,按並選確認創建NetWare分區,然後按直到返回Installation Options視窗。
在NetWare分區上建立和啟動卷:選Volume Options,按,彈出缺省卷SYS後按並回答Yes確認建立卷,按選SYS然後移游標到Status行,在彈出的Volume Status窗口中按選Mount Volume啟動卷。按直到返回Installation Options視窗。
拷貝網路作業系統程式到NetWare卷,依次選擇System Options,Copy System and Public Files並按開始拷貝,當出現:File Upload Complete提示時拷貝結束。按返回Available System Options窗口。
建立Autoexec.ncf文件:選System Options,Create AUTOEXEC.NCF File並按後選Yes確認。
建立STARTUP.NCF文件:依次選System Options,Create STARTUP.NCF File並按後選Yes確認。
按直到退出安裝程式,這時檔伺服器安裝完成。鍵入:
FS:down↓
FS: exit↓
返回DOS。若要啟動檔伺服器,鍵入:
cd\server.312↓
server↓
也可把上述兩句加入autoexec.bat檔,則開機後即自動啟動檔伺服器。
三、安裝工作站客戶軟體
Novell 3.12提供了NetWare Client for DOS/MS-Windows,NetWare Client for OS/2以及NetWare for Macintosh等軟體,使相應的作業系統能訪問NetWare服務,其中NetWare Client for DOS/MS-Windows的工作站連結軟體在MSDOS-1軟體,並使用同一個install批文件,依提示安裝工作站連接軟體。
完成以上步驟後熱啟動,轉到F盤即可註冊進網。
NetWare312無盤站
1、用DOS的FORMAT A:/S/U命令格式化一張軟碟;
2、在該軟碟上拷貝有硬碟的工作站上生成的工作站連結軟體,具體的就是:
config.sys;
autoexec.bat;
DOS目錄和其中的在config.sys和autoexec.bat文件中用到的DOS命令;
NWCLIENT目錄和其中的LSL.com,IPXODI.com,NE2000.com,VLM.exe文件。
3、把config.sys和autoexec.bat文件中C:去掉,該盤即為工作站引導盤。
4、在任一台工作站上,以管理員身份註冊進網;
5、放工作站引導盤到A驅,鍵入:DOSGEN,在sys:system目錄中建立名為NET$DOS.SYS的單獨的啟動映射檔;
6、鍵入:copy net$dos.sys F:\login↓ 拷貝啟動映射檔到SYS:LOGIN目錄;
7、鍵入:CD\login↓和Flag Net$DOS.sys SH/FO↓為NET$DOS.SYS加上可共用屬性;
8、拷貝工作站引導盤上的autoexec.bat檔到用戶入網底稿所指定的目錄。
建立多個遠端啟動映射檔與此類似,這顯然對應於軟硬體配置不同的情形,需要建立各自的工作站引導盤,需要給定各自不同的啟動映射檔案名,並在目錄SYS:LOGIN建立名為BOOTCONF.SYS的文字檔案,內含與遠端啟動映射檔數目相同的行數,每一行格式為:0x網路位址,工作站地址=該工作站的遠端啟動映射檔案名
例如:0x1234,003e678b99=works1.sys
其中網路位址可查autoexec.ncf檔,工作站位址由工作站上網卡的BOOTROM給出。
NetWare312無盤95
一、Win95工作站與Novell網路(NetWare3.12)的連接
(1)關機,打開機箱,安裝網卡
(2)開機,安裝網卡驅動程式
如果所用網卡支援即插即用(Plus&Play),Win95會自動檢測出網卡,我們只鬚根據網卡硬體安裝嚮導安裝網卡驅動程式,並配置好網卡資源:IRQ、I/O地址、DMA通道號。要注意不能與其他硬體資源衝突。若網卡不支援即插即用,則必須手工安裝。在“控制面板”中雙擊“添加新硬體”圖示,然後按提示安裝網卡附帶的驅動程式。
(3)選擇安裝網路協定
網路協定是通信的雙方事先約定好必須遵守的規則,是電腦在網路中相互通信的“語言”。兩台電腦之間必須使用相同的協定才能互相通信。在Win95中安裝IPX/SPX傳輸協議,方法為:在“控制面板”中雙擊“網路”圖示,在“配置”項中按“添加”按鈕,選擇安裝IPX/SPX協定。
(4)選擇安裝客戶
Win95提供的網路用戶端可以使你的電腦連接到目前流行的任何一個網路上去。方法為:在“控制面板”中雙擊“網路”圖示,在“配置”項中按“添加”按鈕添加“NetWare網路用戶端”。
二、Win95工作站在Novell網中的使用
啟動機器,用Novell網路用戶端註冊登錄Novell檔伺服器。雙擊桌面“網路鄰居”圖示,可以流覽Novell檔伺服器共用資源。雙擊桌面“我的電腦”圖示可以看到由Novell共用資源映射成的網路驅動器。
三、安裝無盤啟動Windows95
安裝設置環境:Dong
安裝卷名: SYS
安裝共用目錄:G:\Win95
安裝Windows95目錄:G:\user\user1\windows(G為SYS卷的根目錄)
G:\user\user2\windows
1、安裝Novell伺服器,使其支援Windows95長檔案名,在伺服器控制臺提示符下鍵入:
load OS2
Add Name Space OS2 To SYS(SYS是卷名)
其中load OS2要加入autoexec.ncf中,Add Name Space OS2 To SYS運行一次即可。
2、伺服器上Windows95共用目錄的安裝
在一個有盤Windows95工作站上以管理員身份登錄Novell網路,轉換到含有全版Windows95的光碟中運行Admin\Nettools\Netsetup\Netsetup.exe。
安裝設置如下:
設置路徑:\\DONG\SYS\WIN95(\\伺服器\卷名\安裝目錄)。
選擇伺服器安裝
選擇不創建預設值
輸入產品序列號
然後就進行了伺服器的安裝,複製檔三遍後,再把檔設置為唯讀屬性(安裝自行完成)大概要半小時,即告伺服器安裝完畢。
3、設置msbatch.inf
這是安裝啟動無盤Windows95的最重要的文件之一,安裝成功與否就看該檔的設定了。
在Windows95光碟中運行Admin\Nettools\Netsetup\Batch.exe
安裝設置如下:(未提到的讀者可根據提示自行選擇)
NetWork Options...設置
(1)Available Protocols中選擇IPX/SPX Compatible Protocol。
(2)Available Services中選擇File and Print Sharing for NetWare Networks。
(3)Available Clients中選擇Client for NetWare Networks。
Preferred Server中鍵入伺服器名(如:DONG)
(4)切記選擇Enable Server-Base Setup然後選擇Remote Boot。
(5)選擇OK。
Installation Options...設置
(1)在Setup Options選項中的Type of Installation選擇Custom,Installation Directory選項中鍵入安裝路徑(如:G:\user\user1\windows,切不可填寫G:\win95目錄)。
(2)Time Zone和Monitor Settings選項可自行填寫。
(3)Set...中選擇Stop during setup at the following\Every page(allow customization of all settings)(防止在安裝過程中檢測可能出現的錯誤)。
(4)Uninstall 中選擇Don't create unistall information。
(5)Printers中設置可根據實際情況自行選擇。
Optional components可設置附件及其他的選項。
設置完畢後保存在網路盤符G:\Win95下,並把檔案名改為Msbatch.inf(該檔已在該目錄下存在,首先改掉其唯讀屬性,把其覆蓋即可)。
4、工作站安裝
在一無盤工作站以管理員身份入網(無盤工作站的設置請參閱本站相關資料),在G盤建立一臨時目錄Temp,進入G:\Win95目錄鍵入Setup /T:G:\Temp /is/id開始安裝。切記加上參數/T和臨時目錄,不然就會出現Error Loading Program的提示資訊就退出了,參數/is/id為可選項,其意義可參見Setup/?的幫助資訊。
安裝過程中的資訊其實都是在Msbatch.inf檔中的資訊,不過在檢測硬體時可能會出現檢測通不過現象,如你的機器檢測通不過而又不知是哪種硬體設置原因,就乾脆讓其跳過硬體檢測。檢測過後如有不能識別的設備就幫它設置,最後正式複製檔大概不需要一分鐘就搞定了。工作站的設置就算設定了一大半。
5、設置Machines.ini文件
這是另外一個重要的檔,它負責提供工作的資訊,如果設置不當,照樣不能實現無盤啟動。該文件實際已存在於G:\win95目錄下,用任何文本編輯軟體(如EDIT等打開)。
內容如下:
;Windows95 MACHINES.INI
;[node address]
;SYSDATPATH=x:\
;x=\\server\share
例子如下:
[00002100F425]
SYSDATPATH=G:\user\user2\windows
H=\\DONG\SYS(可省略)
實際上該檔已經把設置格式都告訴給你了,就按其所述格式設計,其中網卡號可由Userlist/A看到或者從伺服器MONITOR中看到。不足12位的在其前加“0”。
切記一點,按其格式設定好後,一定要把它的描述文字刪除,不然就會在啟動過程中出現錯誤資訊然後死機。
6、最後設置
把在g:\user\user1\windows下生成的鏡像檔Net$DOs.sys 複製到G:\LOGIn目錄下,並設置其屬性為共用。如果你想實現DOS和Win95共存,可自行設定Bootconf.sys多重啟動檔,第一台工作站設置完畢。
7、添加其他工作站
把g:\win95目錄共用,然後在有盤的Windows95工作站中按前述步驟設置Msbatch.inf檔,使其安裝路徑改為其他的目錄(如g:\user\user2\windows),或直接在g:\win95目錄下用文本編輯軟體編輯Msbatch.inf檔,改其安裝路徑即可,重新安裝後編輯Machines.ini檔,添加其他的工作站資訊,格式如第一個。其他的工作站即添加完畢。到此為止,你就算全部完成了在Novell網路上啟動無盤Windows95的設定。
一、網卡配置:
為方便安裝,各工作站及伺服器網卡都採用相同配置:NE2000網卡、I/O位址:300H、中斷:3
二、伺服器的安裝:
為伺服器的硬碟上用DOS的FDISK命令分一個不小於50M的DOS分區,其餘硬碟空間不分區。在DOS分區裝好DOS作業系統,如果使用DOS5.0以上的DOS,去掉環境設置中的擴展和延伸記憶體配置。在C盤根目錄用DOS的MD命令生成SERVER.312目錄,並在該目錄下依次生成子目錄UNICODE,SYSTEM-1,SYSTEM-2,SYSTEM-3,SYSTEM-4,SYSTEM-5,SYSTEM-6,SYSTEM-7和SYSTEM-8,並用DOS的XCOPY命令把NetWare 3.12相應的盤拷貝到對應的子目錄下。用DOS的COPY命令拷貝SYSTEM-1盤上的INSTALL.NLM,ISADISK.DSK,SERVER.EXE,KEYB.NLM文件和SYSTEM-3盤上的ETHERTSM.NLM,MSM31X.NLM,NE2000.LAN文件到SERVER.312目錄。
用DOS的CD命令進入SERVER.312目錄,鍵入:SERVER↓ 開始安裝。按螢幕指示鍵入檔伺服器名和網路號。
File server name: FS↓
IPX internal network number:123↓
裝入硬碟卡驅動程式,將不同的硬碟卡需裝入不同的驅動程式,其尾碼名為.DSK,一般的AT-BUS的硬碟卡裝入ISADISK.DSK,中斷及I/O Port值都取缺省值。
FS:load isadisk↓
I/O port: 1FO↓
Interupt number: E↓
裝入網卡驅動程式,不同的網卡需裝入不同的驅動程式,在此用NE2000網卡。
FS:load ne2000↓
I/O port:300↓
Interrupt number:3↓
連接通信協定,並給定網路電纜號:
FS:bind ipx to ne2000↓
NETWORK NUMBER: 1234↓
裝入安裝網路作業系統的安裝程式:
FS:load install↓
依次選擇Disk Options,Partition Tables,Create NetWare Partition項,按
在NetWare分區上建立和啟動卷:選Volume Options,按,彈出缺省卷SYS後按
拷貝網路作業系統程式到NetWare卷,依次選擇System Options,Copy System and Public Files並按
建立Autoexec.ncf文件:選System Options,Create AUTOEXEC.NCF File並按
建立STARTUP.NCF文件:依次選System Options,Create STARTUP.NCF File並按
按
FS:down↓
FS: exit↓
返回DOS。若要啟動檔伺服器,鍵入:
cd\server.312↓
server↓
也可把上述兩句加入autoexec.bat檔,則開機後即自動啟動檔伺服器。
三、安裝工作站客戶軟體
Novell 3.12提供了NetWare Client for DOS/MS-Windows,NetWare Client for OS/2以及NetWare for Macintosh等軟體,使相應的作業系統能訪問NetWare服務,其中NetWare Client for DOS/MS-Windows的工作站連結軟體在MSDOS-1軟體,並使用同一個install批文件,依提示安裝工作站連接軟體。
完成以上步驟後熱啟動,轉到F盤即可註冊進網。
NetWare312無盤站
1、用DOS的FORMAT A:/S/U命令格式化一張軟碟;
2、在該軟碟上拷貝有硬碟的工作站上生成的工作站連結軟體,具體的就是:
config.sys;
autoexec.bat;
DOS目錄和其中的在config.sys和autoexec.bat文件中用到的DOS命令;
NWCLIENT目錄和其中的LSL.com,IPXODI.com,NE2000.com,VLM.exe文件。
3、把config.sys和autoexec.bat文件中C:去掉,該盤即為工作站引導盤。
4、在任一台工作站上,以管理員身份註冊進網;
5、放工作站引導盤到A驅,鍵入:DOSGEN,在sys:system目錄中建立名為NET$DOS.SYS的單獨的啟動映射檔;
6、鍵入:copy net$dos.sys F:\login↓ 拷貝啟動映射檔到SYS:LOGIN目錄;
7、鍵入:CD\login↓和Flag Net$DOS.sys SH/FO↓為NET$DOS.SYS加上可共用屬性;
8、拷貝工作站引導盤上的autoexec.bat檔到用戶入網底稿所指定的目錄。
建立多個遠端啟動映射檔與此類似,這顯然對應於軟硬體配置不同的情形,需要建立各自的工作站引導盤,需要給定各自不同的啟動映射檔案名,並在目錄SYS:LOGIN建立名為BOOTCONF.SYS的文字檔案,內含與遠端啟動映射檔數目相同的行數,每一行格式為:0x網路位址,工作站地址=該工作站的遠端啟動映射檔案名
例如:0x1234,003e678b99=works1.sys
其中網路位址可查autoexec.ncf檔,工作站位址由工作站上網卡的BOOTROM給出。
NetWare312無盤95
一、Win95工作站與Novell網路(NetWare3.12)的連接
(1)關機,打開機箱,安裝網卡
(2)開機,安裝網卡驅動程式
如果所用網卡支援即插即用(Plus&Play),Win95會自動檢測出網卡,我們只鬚根據網卡硬體安裝嚮導安裝網卡驅動程式,並配置好網卡資源:IRQ、I/O地址、DMA通道號。要注意不能與其他硬體資源衝突。若網卡不支援即插即用,則必須手工安裝。在“控制面板”中雙擊“添加新硬體”圖示,然後按提示安裝網卡附帶的驅動程式。
(3)選擇安裝網路協定
網路協定是通信的雙方事先約定好必須遵守的規則,是電腦在網路中相互通信的“語言”。兩台電腦之間必須使用相同的協定才能互相通信。在Win95中安裝IPX/SPX傳輸協議,方法為:在“控制面板”中雙擊“網路”圖示,在“配置”項中按“添加”按鈕,選擇安裝IPX/SPX協定。
(4)選擇安裝客戶
Win95提供的網路用戶端可以使你的電腦連接到目前流行的任何一個網路上去。方法為:在“控制面板”中雙擊“網路”圖示,在“配置”項中按“添加”按鈕添加“NetWare網路用戶端”。
二、Win95工作站在Novell網中的使用
啟動機器,用Novell網路用戶端註冊登錄Novell檔伺服器。雙擊桌面“網路鄰居”圖示,可以流覽Novell檔伺服器共用資源。雙擊桌面“我的電腦”圖示可以看到由Novell共用資源映射成的網路驅動器。
三、安裝無盤啟動Windows95
安裝設置環境:Dong
安裝卷名: SYS
安裝共用目錄:G:\Win95
安裝Windows95目錄:G:\user\user1\windows(G為SYS卷的根目錄)
G:\user\user2\windows
1、安裝Novell伺服器,使其支援Windows95長檔案名,在伺服器控制臺提示符下鍵入:
load OS2
Add Name Space OS2 To SYS(SYS是卷名)
其中load OS2要加入autoexec.ncf中,Add Name Space OS2 To SYS運行一次即可。
2、伺服器上Windows95共用目錄的安裝
在一個有盤Windows95工作站上以管理員身份登錄Novell網路,轉換到含有全版Windows95的光碟中運行Admin\Nettools\Netsetup\Netsetup.exe。
安裝設置如下:
設置路徑:\\DONG\SYS\WIN95(\\伺服器\卷名\安裝目錄)。
選擇伺服器安裝
選擇不創建預設值
輸入產品序列號
然後就進行了伺服器的安裝,複製檔三遍後,再把檔設置為唯讀屬性(安裝自行完成)大概要半小時,即告伺服器安裝完畢。
3、設置msbatch.inf
這是安裝啟動無盤Windows95的最重要的文件之一,安裝成功與否就看該檔的設定了。
在Windows95光碟中運行Admin\Nettools\Netsetup\Batch.exe
安裝設置如下:(未提到的讀者可根據提示自行選擇)
NetWork Options...設置
(1)Available Protocols中選擇IPX/SPX Compatible Protocol。
(2)Available Services中選擇File and Print Sharing for NetWare Networks。
(3)Available Clients中選擇Client for NetWare Networks。
Preferred Server中鍵入伺服器名(如:DONG)
(4)切記選擇Enable Server-Base Setup然後選擇Remote Boot。
(5)選擇OK。
Installation Options...設置
(1)在Setup Options選項中的Type of Installation選擇Custom,Installation Directory選項中鍵入安裝路徑(如:G:\user\user1\windows,切不可填寫G:\win95目錄)。
(2)Time Zone和Monitor Settings選項可自行填寫。
(3)Set...中選擇Stop during setup at the following\Every page(allow customization of all settings)(防止在安裝過程中檢測可能出現的錯誤)。
(4)Uninstall 中選擇Don't create unistall information。
(5)Printers中設置可根據實際情況自行選擇。
Optional components可設置附件及其他的選項。
設置完畢後保存在網路盤符G:\Win95下,並把檔案名改為Msbatch.inf(該檔已在該目錄下存在,首先改掉其唯讀屬性,把其覆蓋即可)。
4、工作站安裝
在一無盤工作站以管理員身份入網(無盤工作站的設置請參閱本站相關資料),在G盤建立一臨時目錄Temp,進入G:\Win95目錄鍵入Setup /T:G:\Temp /is/id開始安裝。切記加上參數/T和臨時目錄,不然就會出現Error Loading Program的提示資訊就退出了,參數/is/id為可選項,其意義可參見Setup/?的幫助資訊。
安裝過程中的資訊其實都是在Msbatch.inf檔中的資訊,不過在檢測硬體時可能會出現檢測通不過現象,如你的機器檢測通不過而又不知是哪種硬體設置原因,就乾脆讓其跳過硬體檢測。檢測過後如有不能識別的設備就幫它設置,最後正式複製檔大概不需要一分鐘就搞定了。工作站的設置就算設定了一大半。
5、設置Machines.ini文件
這是另外一個重要的檔,它負責提供工作的資訊,如果設置不當,照樣不能實現無盤啟動。該文件實際已存在於G:\win95目錄下,用任何文本編輯軟體(如EDIT等打開)。
內容如下:
;Windows95 MACHINES.INI
;[node address]
;SYSDATPATH=x:\
;x=\\server\share
例子如下:
[00002100F425]
SYSDATPATH=G:\user\user2\windows
H=\\DONG\SYS(可省略)
實際上該檔已經把設置格式都告訴給你了,就按其所述格式設計,其中網卡號可由Userlist/A看到或者從伺服器MONITOR中看到。不足12位的在其前加“0”。
切記一點,按其格式設定好後,一定要把它的描述文字刪除,不然就會在啟動過程中出現錯誤資訊然後死機。
6、最後設置
把在g:\user\user1\windows下生成的鏡像檔Net$DOs.sys 複製到G:\LOGIn目錄下,並設置其屬性為共用。如果你想實現DOS和Win95共存,可自行設定Bootconf.sys多重啟動檔,第一台工作站設置完畢。
7、添加其他工作站
把g:\win95目錄共用,然後在有盤的Windows95工作站中按前述步驟設置Msbatch.inf檔,使其安裝路徑改為其他的目錄(如g:\user\user2\windows),或直接在g:\win95目錄下用文本編輯軟體編輯Msbatch.inf檔,改其安裝路徑即可,重新安裝後編輯Machines.ini檔,添加其他的工作站資訊,格式如第一個。其他的工作站即添加完畢。到此為止,你就算全部完成了在Novell網路上啟動無盤Windows95的設定。
2010年4月6日 星期二
2010年4月1日 星期四
GCC 內嵌組合語言介紹
asm__ __volatile__("": : :"memory"); //這句語法是什麼意思,它是內嵌組合語言,我比較不明白的是因為內嵌理頭沒有任何指令,倒是"memory"比較讓我難理解。
先說明語法,內嵌彙編語法如下:
語法可參考http://topic.csdn.net/u/20090521/11/35609357-57b9-4c7c-af6a-04a76eef49a3.html
__asm__(彙編語句範本: 輸出部分: 輸入部分: 破壞描述部分)共四個部分:彙編語句範本,輸出部分,輸入部分,破壞描述部分,各部分使用":"格開,彙編語句範本必不可少,其他三部分可選,如果使用了後面的部分,而前面部分為空,也需要用":"格開,相應部分內容為空。例如:
__asm__ __volatile__("cli": : :"memory")
我一開始不理解其中的"memory"是什麼意思,後來在網上看到說是設置“記憶體屏障”的,並找到了關於"memory"的一段闡述:”memory強制gcc編譯器假設RAM所有記憶體單元均被彙編指令修改,這樣cpu中的registers和cache中已緩存的記憶體單元中的資料將作廢。cpu將不得不在需要的時候重新讀取記憶體中的資料。這就阻止了cpu又將registers,cache中的資料用於去優化指令,而避免去訪問記憶體。”
以下內容源自:http://hi.baidu.com/hilyjiang/blog/item/7db5077a8180dbec2e73b380.html
__asm__ __volatile__ GCC的內嵌彙編語法 AT&T組合語言語法(一)
開發一個OS,儘管絕大部分代碼只需要用C/C++等高階語言就可以了,但至少和硬體相關部分的代碼需要使用組合語言,另外,由於啟動部分的代碼有大小限制,使用精練的彙編可以縮小目標代碼的Size。另外,對於某些需要被經常調用的代碼,使用彙編來寫可以提高性能。所以我們必須瞭解組合語言,即使你有可能並不喜歡它。
如果你是電腦專業的話,在大學裏你應該學習過Intel格式的8086/80386彙編,這裏就不再討論。如果我們選擇的OS開發工具是GCC以及GAS的話,就必須瞭解AT&T組合語言語法,因為GCC/GAS只支援這種彙編語法。
本書不會去討論8086/80386的彙編編程,這類的書籍很多,你可以參考它們。這裏只會討論AT&T的彙編語法,以及GCC的內嵌彙編語法。
--------------------------------------------------------------------------------
0.3.2 Syntax
1.寄存器引用
引用寄存器要在寄存器號前加百分號%,如“movl %eax, %ebx”。
80386有如下寄存器:
8個32-bit寄存器 %eax,%ebx,%ecx,%edx,%edi,%esi,%ebp,%esp;
8個16-bit寄存器,它們事實上是上面8個32-bit寄存器的低16位:%ax,%bx,%cx,%dx,%di,%si,%bp,%sp;
8個8-bit寄存器:%ah,%al,%bh,%bl,%ch,%cl,%dh,%dl。它們事實上是寄存器%ax,%bx,%cx,%dx的高8位和低8位;
6個段寄存器:%cs(code),%ds(data),%ss(stack), %es,%fs,%gs;
3個控制寄存器:%cr0,%cr2,%cr3;
6個debug寄存器:%db0,%db1,%db2,%db3,%db6,%db7;
2個測試寄存器:%tr6,%tr7;
8個浮點寄存器棧:%st(0),%st(1),%st(2),%st(3),%st(4),%st(5),%st(6),%st(7)。
2. 運算元順序
運算元排列是從源(左)到目的(右),如“movl %eax(源), %ebx(目的)”
3. 立即數
使用立即數,要在數前面加符號$, 如“movl $0x04, %ebx”
或者:
para = 0x04
movl $para, %ebx
指令執行的結果是將立即數04h裝入寄存器ebx。
4. 符號常數
符號常數直接引用如
value: .long 0x12a3f2de
movl value , %ebx
指令執行的結果是將常數0x12a3f2de裝入寄存器ebx。
引用符號位址在符號前加符號$, 如“movl $value, % ebx”則是將符號value的位址裝入寄存器ebx。
5. 運算元的長度
運算元的長度用加在指令後的符號表示b(byte, 8-bit), w(word, 16-bits), l(long, 32-bits),如“movb %al, %bl”,“movw %ax, %bx”,“movl %eax, %ebx ”。
如 果沒有指定運算元長度的話,編譯器將按照目標運算元的長度來設置。比如指令“mov %ax, %bx”,由於目標運算元bx的長度為word,那麼編譯器將把此指令等同於“movw %ax, %bx”。同樣道理,指令“mov $4, %ebx”等同於指令“movl $4, %ebx”,“push %al”等同於“pushb %al”。對於沒有指定運算元長度,但編譯器又無法猜測的指令,編譯器將會報錯,比如指令“push $4”。
6. 符號擴展和零擴展指令
絕大多數面向80386的AT&T彙編指令與Intel格式的彙編指令都是相同的,符號擴展指令和零擴展指令則是僅有的不同格式指令。
符號擴展指令和零擴展指令需要指定源運算元長度和目的運算元長度,即使在某些指令中這些運算元是隱含的。
在AT& T語法中,符號擴展和零擴展指令的格式為,基本部分"movs"和"movz"(對應Intel語法的movsx和movzx),後面跟上源運算元長度和 目的運算元長度。movsbl意味著movs (from)byte (to)long;movbw意味著movs (from)byte (to)word;movswl意味著movs (from)word (to)long。對於movz指令也一樣。比如指令“movsbl %al, %edx”意味著將al寄存器的內容進行符號擴展後放置到edx寄存器中。
其他的Intel格式的符號擴展指令還有:
cbw -- sign-extend byte in %al to word in %ax;
cwde -- sign-extend word in %ax to long in %eax;
cwd -- sign-extend word in %ax to long in %dx:%ax;
cdq -- sign-extend dword in %eax to quad in %edx:%eax;
對應的AT&T語法的指令為cbtw,cwtl,cwtd,cltd。
7. 調用和跳轉指令
段內調用和跳轉指令為"call","ret"和"jmp",段間調用和跳轉指令為"lcall","lret"和"ljmp"。
段間調用和跳轉指令的格式為“lcall/ljmp $SECTION, $OFFSET”,而段間返回指令則為“lret $STACK-ADJUST”。
8. 首碼
操作碼首碼被用在下列的情況:
字串重複操作指令(rep,repne);
指定被操作的段(cs,ds,ss,es,fs,gs);
進行匯流排加鎖(lock);
指定位址和操作的大小(data16,addr16);
在AT&T彙編語法中,操作碼首碼通常被單獨放在一行,後面不跟任何運算元。例如,對於重複scas指令,其寫法為:
repne
scas
上述操作碼首碼的意義和用法如下:
指定被操作的段首碼為cs,ds,ss,es,fs,和gs。在AT&T語法中,只需要按照section:memory-operand的格式就指定了相應的段首碼。比如:lcall %cs:realmode_swtch
運算元/位址大小首碼是“data16”和"addr16",它們被用來在32-bit運算元/地址代碼中指定16-bit的運算元/地址。
總 線加鎖首碼“lock”,它是為了在多處理器環境中,保證在當前指令執行期間禁止一切中斷。這個首碼僅僅對ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG,DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD,XCHG指令有效,如果將Lock首碼用在其他指令之前,將會引起異常。
字串重複操作首碼"rep","repe","repne"用來讓字串操作重複“%ecx”次。
9. 記憶體引用
Intel語法的間接記憶體引用的格式為:
section:[base+index*scale+displacement]
而在AT&T語法中對應的形式為:
section:displacement(base,index,scale)
其 中,base和index是任意的32-bit base和index寄存器。scale可以取值1,2,4,8。如果不指定scale值,則預設值為1。section可以指定任意的段寄存器作為段首碼,默認的段寄存器在不同的情況下不一樣。如果你在指令中指定了默認的段首碼,則編譯器在目標代碼中不會產生此段首碼代碼。
下面是一些例子:
-4(%ebp):base=%ebp,displacement=-4,section沒有指定,由於base=%ebp,所以默認的section=%ss,index,scale沒有指定,則index為0。
foo(,%eax,4):index=%eax,scale=4,displacement=foo。其他域沒有指定。這裏默認的section=%ds。
foo(,1):這個運算式引用的是指標foo指向的位址所存放的值。注意這個運算式中沒有base和index,並且只有一個逗號,這是一種異常語法,但卻合法。
%gs:foo:這個運算式引用的是放置于%gs段裏變數foo的值。
如果call和jump操作在運算元前指定首碼“*”,則表示是一個絕對位址調用/跳轉,也就是說jmp/call指令指定的是一個絕對位址。如果沒有指定"*",則運算元是一個相對位址。
任何指令如果其運算元是一個記憶體操作,則指令必須指定它的操作尺寸(byte,word,long),也就是說必須帶有指令尾碼(b,w,l)。
.3 GCC Inline ASM
GCC 支持在C/C++代碼中嵌入彙編代碼,這些彙編代碼被稱作GCC Inline ASM——GCC內聯彙編。這是一個非常有用的功能,有利於我們將一些C/C++語法無法表達的指令直接潛入C/C++代碼中,另外也允許我們直接寫 C/C++代碼中使用彙編編寫簡潔高效的代碼。
1.基本內聯彙編
GCC中基本的內聯彙編非常易懂,我們先來看兩個簡單的例子:
__asm__("movl %esp,%eax"); // 看起來很熟悉吧
或者是
__asm__("
movl $1,%eax // SYS_exit
xor %ebx,%ebx
int $0x80
");
或
__asm__(
"movl $1,%eax\r\t" \
"xor %ebx,%ebx\r\t" \
"int $0x80" \
);
基本內聯彙編的格式是
__asm__ __volatile__("Instruction List");
1、__asm__
__asm__是GCC關鍵字asm的巨集定義:
#define __asm__ asm
__asm__或asm用來聲明一個內聯彙編運算式,所以任何一個內聯彙編運算式都是以它開頭的,是必不可少的。
2、Instruction List
Instruction List是彙編指令序列。它可以是空的,比如:__asm__ __volatile__(""); 或__asm__ ("");都是完全合法的內聯彙編運算式,只不過這兩條語句沒有什麼意義。但並非所有Instruction List為空的內聯彙編運算式都是沒有意義的,比如:__asm__ ("":::"memory"); 就非常有意義,它向GCC聲明:“我對記憶體作了改動”,GCC在編譯的時候,會將此因素考慮進去。
我們看一看下面這個例子:
$ cat example1.c
int main(int __argc, char* __argv[])
{
int* __p = (int*)__argc;
(*__p) = 9999;
//__asm__("":::"memory");
if((*__p) == 9999)
return 5;
return (*__p);
}
在 這段代碼中,那條內聯彙編是被注釋掉的。在這條內聯彙編之前,記憶體指標__p所指向的記憶體被賦值為9999,隨即在內聯彙編之後,一條if語句判斷__p 所指向的記憶體與9999是否相等。很明顯,它們是相等的。GCC在優化編譯的時候能夠很聰明的發現這一點。我們使用下面的命令行對其進行編譯:
$ gcc -O -S example1.c
選項-O表示優化編譯,我們還可以指定優化等級,比如-O2表示優化等級為2;選項-S表示將C/C++原始檔案編譯為彙編檔,檔案名和C/C++文件一樣,只不過副檔名由.c變為.s。
我們來查看一下被放在example1.s中的編譯結果,我們這裏僅僅列出了使用gcc 2.96在redhat 7.3上編譯後的相關函數部分彙編代碼。為了保持清晰性,無關的其他代碼未被列出。
$ cat example1.s
main:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax # int* __p = (int*)__argc
movl $9999, (%eax) # (*__p) = 9999
movl $5, %eax # return 5
popl %ebp
ret
參 照一下C源碼和編譯出的彙編代碼,我們會發現彙編代碼中,沒有if語句相關的代碼,而是在賦值語句(*__p)=9999後直接return 5;這是因為GCC認為在(*__p)被賦值之後,在if語句之前沒有任何改變(*__p)內容的操作,所以那條if語句的判斷條件(*__p) == 9999肯定是為true的,所以GCC就不再生成相關代碼,而是直接根據為true的條件生成return 5的彙編代碼(GCC使用eax作為保存返回值的寄存器)。
我們現在將example1.c中內聯彙編的注釋去掉,重新編譯,然後看一下相關的編譯結果。
$ gcc -O -S example1.c
$ cat example1.s
main:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax # int* __p = (int*)__argc
movl $9999, (%eax) # (*__p) = 9999
#APP
# __asm__("":::"memory")
#NO_APP
cmpl $9999, (%eax) # (*__p) == 9999 ?
jne .L3 # false
movl $5, %eax # true, return 5
jmp .L2
.p2align 2
.L3:
movl (%eax), %eax
.L2:
popl %ebp
ret
由於內聯彙編語句__asm__("":::"memory")向GCC聲明,在此內聯彙編語句出現的位置記憶體內容可能了改變,所以GCC在編譯時就不能像剛才那樣處理。這次,GCC老老實實的將if語句生成了彙編代碼。
可能有人會質疑:為什麼要使用__asm__("":::"memory")向GCC聲明記憶體發生了變化?明明“Instruction List”是空的,沒有任何對記憶體的操作,這樣做只會增加GCC生成彙編代碼的數量。
確 實,那條內聯彙編語句沒有對記憶體作任何操作,事實上它確實什麼都沒有做。但影響記憶體內容的不僅僅是你當前正在運行的程式。比如,如果你現在正在操作的記憶體是一塊記憶體映射,映射的內容是週邊I/O設備寄存器。那麼操作這塊記憶體的就不僅僅是當前的程式,I/O設備也會去操作這塊記憶體。既然兩者都會去操作同一塊 記憶體,那麼任何一方在任何時候都不能對這塊記憶體的內容想當然。所以當你使用高階語言C/C++寫這類程式的時候,你必須讓編譯器也能夠明白這一點,畢竟高 級語言最終要被編譯為彙編代碼。
你可能已經注意到了,這次輸出的彙編結果中,有兩個符號:#APP和#NO_APP,GCC將內聯彙編語句中"Instruction List"所列出的指令放在#APP和#NO_APP之間,由於__asm__("":::"memory")中“Instruction List”為空,所以#APP和#NO_APP中間也沒有任何內容。但我們以後的例子會更加清楚的表現這一點。
關於為什麼內聯彙編__asm__("":::"memory")是一條聲明記憶體改變的語句,我們後面會詳細討論。
剛才我們花了大量的內容來討論"Instruction List"為空是的情況,但在實際的編程中,"Instruction List"絕大多數情況下都不是空的。它可以有1條或任意多條彙編指令。
當 在"Instruction List"中有多條指令的時候,你可以在一對引號中列出全部指令,也可以將一條或幾條指令放在一對引號中,所有指令放在多對引號中。如果是前者,你可以將每一條指令放在一行,如果要將多條指令放在一行,則必須用分號(;)或換行符(\n,大多數情況下\n後還要跟一個\t,其中\n是為了換行,\t是為了 空出一個tab寬度的空格)將它們分開。比如:
__asm__("movl %eax, %ebx
sti
popl %edi
subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti
popl %edi; subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi
subl %ecx, %ebx");
都是合法的寫法。如果你將指令放在多對引號中,則除了最後一對引號之外,前面的所有引號裏的最後一條指令之後都要有一個分號(;)或(\n)或(\n\t)。比如:
__asm__("movl %eax, %ebx
sti\n"
"popl %edi;"
"subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t"
"popl %edi; subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi\n"
"subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi;" "subl %ecx, %ebx");
都是合法的。
上述原則可以歸結為:
任意兩個指令間要麼被分號(;)分開,要麼被放在兩行;
放在兩行的方法既可以從通過\n的方法來實現,也可以真正的放在兩行;
可以使用1對或多對引號,每1對引號裏可以放任一多條指令,所有的指令都要被放到引號中。
在基本內聯彙編中,“Instruction List”的書寫的格式和你直接在彙編檔中寫非內聯彙編沒有什麼不同,你可以在其中定義Label,定義對齊(.align n ),定義段(.section name )。例如:
__asm__(".align 2\n\t"
"movl %eax, %ebx\n\t"
"test %ebx, %ecx\n\t"
"jne error\n\t"
"sti\n\t"
"error: popl %edi\n\t"
"subl %ecx, %ebx");
上面例子的格式是Linux內聯代碼常用的格式,非常整齊。也建議大家都使用這種格式來寫內聯彙編代碼。
3、__volatile__
__volatile__是GCC關鍵字volatile的巨集定義:
#define __volatile__ volatile
__volatile__ 或volatile是可選的,你可以用它也可以不用它。如果你用了它,則是向GCC聲明“不要動我所寫的Instruction List,我需要原封不動的保留每一條指令”,否則當你使用了優化選項(-O)進行編譯時,GCC將會根據自己的判斷決定是否將這個內聯彙編運算式中的指 令優化掉。
那麼GCC判斷的原則是什麼?我不知道(如果有哪位朋友清楚的話,請告訴我)。我試驗了一下,發現一條內聯彙編語句如果是基本 內聯彙編的話(即只有“Instruction List”,沒有Input/Output/Clobber的內聯彙編,我們後面將會討論這一點),無論你是否使用__volatile__來修飾, GCC 2.96在優化編譯時,都會原封不動的保留內聯彙編中的“Instruction List”。但或許我的試驗的例子並不充分,所以這一點並不能夠得到保證。
為了保險起見,如果你不想讓GCC的優化影響你的內聯彙編代碼,你最好在前面都加上__volatile__,而不要依賴於編譯器的原則,因為即使你非常瞭解當前編譯器的優化原則,你也無法保證這種原則將來不會發生變化。而__volatile__的含義卻是恒定的。
2、帶有C/C++運算式的內聯彙編
GCC允許你通過C/C++運算式指定內聯彙編中"Instrcuction List"中指令的輸入和輸出,你甚至可以不關心到底使用哪個寄存器被使用,完全靠GCC來安排和指定。這一點可以讓程式師避免去考慮有限的寄存器的使用,也可以提高目標代碼的效率。
我們先來看幾個例子:
__asm__ (" " : : : "memory" ); // 前面提到的
__asm__ ("mov %%eax, %%ebx" : "=b"(rv) : "a"(foo) : "eax", "ebx");
__asm__ __volatile__("lidt %0": "=m" (idt_descr));
__asm__("subl %2,%0\n\t"
"sbbl %3,%1"
: "=a" (endlow), "=d" (endhigh)
: "g" (startlow), "g" (starthigh), "0" (endlow), "1" (endhigh));
怎麼樣,有點印象了吧,是不是也有點暈?沒關係,下面討論完之後你就不會再暈了。(當然,也有可能更暈^_^)。討論開始——
帶有C/C++運算式的內聯彙編格式為:
__asm__ __volatile__("Instruction List" : Output : Input : Clobber/Modify);
從中我們可以看出它和基本內聯彙編的不同之處在於:它多了3個部分(Input,Output,Clobber/Modify)。在括弧中的4個部分通過冒號(:)分開。
這4個部分都不是必須的,任何一個部分都可以為空,其規則為:
如 果Clobber/Modify為空,則其前面的冒號(:)必須省略。比如__asm__("mov %%eax, %%ebx" : "=b"(foo) : "a"(inp) : )就是非法的寫法;而__asm__("mov %%eax, %%ebx" : "=b"(foo) : "a"(inp) )則是正確的。
如果Instruction List為空,則Input,Output,Clobber/Modify可以不為空,也可以為空。比如__asm__ ( " " : : : "memory" );和__asm__(" " : : );都是合法的寫法。
如 果Output,Input,Clobber/Modify都為空,Output,Input之前的冒號(:)既可以省略,也可以不省略。如果都省略,則此彙編退化為一個基本內聯彙編,否則,仍然是一個帶有C/C++運算式的內聯彙編,此時"Instruction List"中的寄存器寫法要遵守相關規定,比如寄存器前必須使用兩個百分號(%%),而不是像基本彙編格式一樣在寄存器前只使用一個百分號(%)。比如 __asm__( " mov %%eax, %%ebx" : : );__asm__( " mov %%eax, %%ebx" : )和__asm__( " mov %eax, %ebx" )都是正確的寫法,而__asm__( " mov %eax, %ebx" : : );__asm__( " mov %eax, %ebx" : )和__asm__( " mov %%eax, %%ebx" )都是錯誤的寫法。
如果Input,Clobber/Modify為空,但Output不為空,Input前的冒號(:)既可以省略,也可以不省略。比如 __asm__( " mov %%eax, %%ebx" : "=b"(foo) : );__asm__( " mov %%eax, %%ebx" : "=b"(foo) )都是正確的。
如果後面的部分不為空,而前面的部分為空,則前面的冒號(:)都必須保留,否則無法說 明不為空的部分究竟是第幾部分。比如, Clobber/Modify,Output為空,而Input不為空,則Clobber/Modify前的冒號必須省略(前面的規則),而Output 前的冒號必須為保留。如果Clobber/Modify不為空,而Input和Output都為空,則Input和Output前的冒號都必須保留。比如 __asm__( " mov %%eax, %%ebx" : : "a"(foo) )和__asm__( " mov %%eax, %%ebx" : : : "ebx" )。
從上面的規則可以看到另外一個事實,區分一個內聯彙編是基本格式的還是帶有C/C++運算式格式的,其規則在於在"Instruction List"後是否有冒號(:)的存在,如果沒有則是基本格式的,否則,則是帶有C/C++運算式格式的。
兩種格式對寄存器語法的要求不同:基本格式要求寄存器前只能使用一個百分號(%),這一點和非內聯彙編相同;而帶有C/C++運算式格式則要求寄存器前必須使用兩個百分號(%%),其原因我們會在後面討論。
1. Output
Output用來指定當前內聯彙編語句的輸出。我們看一看這個例子:
__asm__("movl %%cr0, %0": "=a" (cr0));
這 個內聯彙編語句的輸出部分為"=r"(cr0),它是一個“操作運算式”,指定了一個輸出操作。我們可以很清楚得看到這個輸出操作由兩部分組成:括弧括住 的部分(cr0)和引號引住的部分"=a"。這兩部分都是每一個輸出操作必不可少的。括弧括住的部分是一個C/C++運算式,用來保存內聯彙編的一個輸出值,其操作就等於C/C++的相等賦值cr0 = output_value,因此,括弧中的輸出運算式只能是C/C++的左值運算式,也就是說它只能是一個可以合法的放在C/C++賦值操作中等號(=) 左邊的運算式。那麼右值output_value從何而來呢?
答案是引號中的內容,被稱作“操作約束”(Operation Constraint),在這個例子中操作約束為"=a",它包含兩個約束:等號(=)和字母a,其中等號(=)說明括弧中左值運算式cr0是一個 Write-Only的,只能夠被作為當前內聯彙編的輸入,而不能作為輸入。而字母a是寄存器EAX / AX / AL的簡寫,說明cr0的值要從eax寄存器中獲取,也就是說cr0 = eax,最終這一點被轉化成彙編指令就是movl %eax, address_of_cr0。現在你應該清楚了吧,操作約束中會給出:到底從哪個寄存器傳遞值給cr0。
另外,需要特別說明的是,很多文檔都聲明,所有輸出操作的操作約束必須包含一個等號(=),但GCC的文檔中卻很清楚的聲明,並非如此。因為等號(=)約束說明當前的運算式是一個 Write-Only的,但另外還有一個符號——加號(+)用來說明當前運算式是一個Read-Write的,如果一個操作約束中沒有給出這兩個符號中的任何一個,則說明當前運算式是Read-Only的。因為對於輸出操作來說,肯定是必須是可寫的,而等號(=)和加號(+)都表示可寫,只不過加號(+) 同時也表示是可讀的。所以對於一個輸出操作來說,其操作約束只需要有等號(=)或加號(+)中的任意一個就可以了。
二者的區別是:等號(=)表示當前操作運算式指定了一個純粹的輸出操作,而加號(+)則表示當前操作運算式不僅僅只是一個輸出操作還是一個輸入操作。但無論是等號(=)約束還是加號(+)約束所約束的操作運算式都只能放在Output域中,而不能被用在Input域中。
另外,有些文檔聲明:儘管GCC文檔中提供了加號(+)約束,但在實際的編譯中通不過;我不知道老版本會怎麼樣,我在GCC 2.96中對加號(+)約束的使用非常正常。
我們通過一個例子看一下,在一個輸出操作中使用等號(=)約束和加號(+)約束的不同。
$ cat example2.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %%cr0, %0":"=a" (cr0));
return 0;
}
$ gcc -S example2.c
$ cat example2.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
#APP
movl %cr0, %eax
#NO_APP
movl %eax, %eax
movl %eax, -4(%ebp) # cr0 = %eax
movl $0, %eax
leave
ret
這個例子是使用等號(=)約束的情況,變數cr0被放在記憶體-4(%ebp)的位置,所以指令mov %eax, -4(%ebp)即表示將%eax的內容輸出到變數cr0中。
下面是使用加號(+)約束的情況:
$ cat example3.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %%cr0, %0" : "+a" (cr0));
return 0;
}
$ gcc -S example3.c
$ cat example3.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
movl -4(%ebp), %eax # input ( %eax = cr0 )
#APP
movl %cr0, %eax
#NO_APP
movl %eax, -4(%ebp) # output (cr0 = %eax )
movl $0, %eax
leave
ret
從編譯的結果可以看出,當使用加號(+)約束的時候,cr0不僅作為輸出,還作為輸入,所使用寄存器都是寄存器約束(字母a,表示使用eax寄存器)指定的。關於寄存器約束我們後面討論。
在Output域中可以有多個輸出操作運算式,多個操作運算式中間必須用逗號(,)分開。例如:
__asm__(
"movl %%eax, %0 \n\t"
"pushl %%ebx \n\t"
"popl %1 \n\t"
"movl %1, %2"
: "+a"(cr0), "=b"(cr1), "=c"(cr2));
2、Input
Input域的內容用來指定當前內聯彙編語句的輸入。我們看一看這個例子:
__asm__("movl %0, %%db7" : : "a" (cpu->db7));
例中Input域的內容為一個運算式"a"[cpu->db7),被稱作“輸入運算式”,用來表示一個對當前內聯彙編的輸入。
像輸出運算式一樣,一個輸入運算式也分為兩部分:帶括弧的部分(cpu->db7)和帶引號的部分"a"。這兩部分對於一個內聯彙編輸入運算式來說也是必不可少的。
括 號中的運算式cpu->db7是一個C/C++語言的運算式,它不必是一個左值運算式,也就是說它不僅可以是放在C/C++賦值操作左邊的運算式, 還可以是放在C/C++賦值操作右邊的運算式。所以它可以是一個變數,一個數位,還可以是一個複雜的運算式(比如a+b/c*d)。比如上例可以改為: __asm__("movl %0, %%db7" : : "a" (foo)),__asm__("movl %0, %%db7" : : "a" (0x1000))或__asm__("movl %0, %%db7" : : "a" (va*vb/vc))。
引號號中的部分是約束部分,和輸出運算式約束不同的是,它不允許指定加號(+)約束和等號(=)約束,也就是說它只能是默認的Read-Only的。約束中必須指定 一個寄存器約束,例中的字母a表示當前輸入變數cpu->db7要通過寄存器eax輸入到當前內聯彙編中。
我們看一個例子:
$ cat example4.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %0, %%cr0"::"a" (cr0));
return 0;
}
$ gcc -S example4.c
$ cat example4.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
movl -4(%ebp), %eax # %eax = cr0
#APP
movl %eax, %cr0
#NO_APP
movl $0, %eax
leave
ret
我們從編譯出的彙編代碼可以看到,在"Instruction List"之前,GCC按照我們的輸入約束"a",將變數cr0的內容裝入了eax寄存器。
3. Operation Constraint
每一個Input和Output運算式都必須指定自己的操作約束Operation Constraint,我們這裏來討論在80386平臺上所可能使用的操作約束。
1、寄存器約束
當你當前的輸入或輸入需要借助一個寄存器時,你需要為其指定一個寄存器約束。你可以直接指定一個寄存器的名字,比如:
__asm__ __volatile__("movl %0, %%cr0"::"eax" (cr0));
也可以指定一個縮寫,比如:
__asm__ __volatile__("movl %0, %%cr0"::"a" (cr0));
如果你指定一個縮寫,比如字母a,則GCC將會根據當前操作運算式中C/C++運算式的寬度決定使用%eax,還是%ax或%al。比如:
unsigned short __shrt;
__asm__ ("mov %0,%%bx" : : "a"(__shrt));
由於變數__shrt是16-bit short類型,則編譯出來的彙編代碼中,則會讓此變數使用%ex寄存器。編譯結果為:
movw -2(%ebp), %ax # %ax = __shrt
#APP
movl %ax, %bx
#NO_APP
無論是Input,還是Output操作運算式約束,都可以使用寄存器約束。
下表中列出了常用的寄存器約束的縮寫。
約束 Input/Output 意義
r I,O 表示使用一個通用寄存器,由GCC在%eax/%ax/%al, %ebx/%bx/%bl, %ecx/%cx/%cl, %edx/%dx/%dl中選取一個GCC認為合適的。
q I,O 表示使用一個通用寄存器,和r的意義相同。
a I,O 表示使用%eax / %ax / %al
b I,O 表示使用%ebx / %bx / %bl
c I,O 表示使用%ecx / %cx / %cl
d I,O 表示使用%edx / %dx / %dl
D I,O 表示使用%edi / %di
S I,O 表示使用%esi / %si
f I,O 表示使用浮點寄存器
t I,O 表示使用第一個浮點寄存器
u I,O 表示使用第二個浮點寄存器
2、記憶體約束
如果一個Input/Output操作運算式的C/C++運算式表現為一個記憶體位址,不想借助於任何寄存器,則可以使用記憶體約束。比如:
__asm__ ("lidt %0" : "=m"(__idt_addr)); 或 __asm__ ("lidt %0" : :"m"(__idt_addr));
我們看一下它們分別被放在一個C原始檔案中,然後被GCC編譯後的結果:
$ cat example5.c
// 本例中,變數sh被作為一個記憶體輸入
int main(int __argc, char* __argv[])
{
char* sh = (char*)&__argc;
__asm__ __volatile__("lidt %0" : : "m" (sh));
return 0;
}
$ gcc -S example5.c
$ cat example5.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
leal 8(%ebp), %eax
movl %eax, -4(%ebp) # sh = (char*) &__argc
#APP
lidt -4(%ebp)
#NO_APP
movl $0, %eax
leave
ret
$ cat example6.c
// 本例中,變數sh被作為一個記憶體輸出
int main(int __argc, char* __argv[])
{
char* sh = (char*)&__argc;
__asm__ __volatile__("lidt %0" : "=m" (sh));
return 0;
}
$ gcc -S example6.c
$ cat example6.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
leal 8(%ebp), %eax
movl %eax, -4(%ebp) # sh = (char*) &__argc
#APP
lidt -4(%ebp)
#NO_APP
movl $0, %eax
leave
ret
首先,你會注意到,在這兩個例子中,變數sh沒有借助任何寄存器,而是直接參與了指令lidt的操作。
其次,通過仔細觀察,你會發現一個驚人的事實,兩個例子編譯出來的彙編代碼是一樣的!雖然,一個例子中變數sh作為輸入,而另一個例子中變數sh作為輸出。這是怎麼回事?
原來,使用記憶體方式進行輸入輸出時,由於不借助寄存器,所以GCC不會按照你的聲明對其作任何的輸入輸出處理。GCC只會直接拿來用,究竟對這個C/C++運算式而言是輸入還是輸出,完全依賴與你寫在"Instruction List"中的指令對其操作的指令。
由 於上例中,對其操作的指令為lidt,lidt指令的運算元是一個輸入型的運算元,所以事實上對變數sh的操作是一個輸入操作,即使你把它放在 Output域也不會改變這一點。所以,對此例而言,完全符合語意的寫法應該是將sh放在Input域,儘管放在Output域也會有正確的執行結果。
所 以,對於記憶體約束類型的操作運算式而言,放在Input域還是放在Output域,對編譯結果是沒有任何影響的,因為本來我們將一個操作運算式放在 Input域或放在Output域是希望GCC能為我們自動通過寄存器將運算式的值輸入或輸出。既然對於記憶體約束類型的操作運算式來說,GCC不會自動為 它做任何事情,那麼放在哪兒也就無所謂了。但從程式師的角度而言,為了增強代碼的可讀性,最好能夠把它放在符合實際情況的地方。
約束 Input/Output 意義
m I,O 表示使用系統所支援的任何一種記憶體方式,不需要借助寄存器
__asm__ __volatile__ GCC的內嵌彙編語法 AT&T組合語言語法(二)
3、立即數約束
如果一個Input/Output操作運算式的C/C++運算式是一個數字常數,不想借助於任何寄存器,則可以使用立即數約束。
由於立即數在C/C++中只能作為右值,所以對於使用立即數約束的運算式而言,只能放在Input域。
比如:__asm__ __volatile__("movl %0, %%eax" : : "i" (100) );
立即數約束很簡單,也很容易理解,我們在這裏就不再贅述。
約束 Input/Output 意義
i I 表示輸入運算式是一個立即數(整數),不需要借助任何寄存器
F I 表示輸入運算式是一個立即數(浮點數),不需要借助任何寄存器
4、通用約束
約束 Input/Output 意義
g I,O 表示可以使用通用寄存器,記憶體,立即數等任何一種處理方式。
0,1,2,3,4,5,6,7,8,9 I 表示和第n個操作運算式使用相同的寄存器/記憶體。
通用約束g是一個非常靈活的約束,當程式師認為一個C/C++運算式在實際的操作中,究竟使用寄存器方式,還是使用記憶體方式或立即數方式並無所謂時,或者程式師想實現一個靈活的範本,讓GCC可以根據不同的C/C++運算式生成不同的訪問方式時,就可以使用通用約束g。比如:
#define JUST_MOV(foo) __asm__ ("movl %0, %%eax" : : "g"(foo))
JUST_MOV(100)和JUST_MOV(var)則會讓編譯器產生不同的代碼。
int main(int __argc, char* __argv[])
{
JUST_MOV(100);
return 0;
}
編譯後生成的代碼為:
main:
pushl %ebp
movl %esp, %ebp
#APP
movl $100, %eax
#NO_APP
movl $0, %eax
popl %ebp
ret
很明顯這是立即數方式。而下一個例子:
int main(int __argc, char* __argv[])
{
JUST_MOV(__argc);
return 0;
}
經編譯後生成的代碼為:
main:
pushl %ebp
movl %esp, %ebp
#APP
movl 8(%ebp), %eax
#NO_APP
movl $0, %eax
popl %ebp
ret
這個例子是使用記憶體方式。
一個帶有C/C++運算式的內聯彙編,其操作運算式被按照被列出的順序編號,第一個是0,第2個是1,依次類推,GCC最多允許有10個操作運算式。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=a"(__out)
: "r" (__in1), "r" (__in2));
此例中,__out所在的Output操作運算式被編號為0,"r"(__in1)被編號為1,"r"(__in2)被編號為2。
再如:
__asm__ ("movl %%eax, %%ebx" : : "a"(__in1), "b"(__in2));
此例中,"a"(__in1)被編號為0,"b"(__in2)被編號為1。
如果某個Input操作運算式使用數字0到9中的一個數字(假設為1)作為它的操作約束,則等於向GCC聲明:“我要使用和編號為1的Output操作表達式相同的寄存器(如果Output操作運算式1使用的是寄存器),或相同的記憶體位址(如果Output操作運算式1使用的是記憶體)”。上面的描述包含兩個限定:數位0到數位9作為操作約束只能用在Input操作運算式中,被指定的操作運算式(比如某個Input操作運算式使用數位1作為約束,那麼被指定的 就是編號為1的操作運算式)只能是Output操作運算式。
由於GCC規定最多只能有10個Input/Output操作運算式,所以事實上數字9作為操作約束永遠也用不到,因為Output操作運算式排在Input操作運算式的前面,那麼如果有一個Input操作運算式指定了數字9作為 操作約束的話,那麼說明Output操作運算式的數量已經至少為10個了,那麼再加上這個Input操作運算式,則至少為11個了,以及超出GCC的限 制。
5、Modifier Characters(修飾符)
等號(=)和加號(+)用於對Output操作運算式的修飾,一個Output操作運算式要麼被等號(=)修飾,要麼被加號(+)修飾,二者必居其一。使用等號(=)說明此Output操作運算式是Write- Only的,使用加號(+)說明此Output操作運算式是Read-Write的。它們必須被放在約束字串的第一個字母。比如"a="(foo)是非 法的,而"+g"(foo)則是合法的。
當使用加號(+)的時候,此Output運算式等價於使用等號(=)約束加上一個Input運算式。比如
__asm__ ("movl %0, %%eax; addl %%eax, %0" : "+b"(foo)) 等價於
__asm__ ("movl %1, %%eax; addl %%eax, %0" : "=b"(foo) : "b"(foo))
但如果使用後一種寫法,"Instruction List"中的別名也要相應的改動。關於別名,我們後面會討論。
像等號(=)和加號(+)修飾符一樣,符號(&)也只能用於對Output操作運算式的修飾。當使用它進行修飾時,等於向GCC聲明:"GCC不得 為任何Input操作運算式分配與此Output操作運算式相同的寄存器"。其原因是&修飾符意味著被其修飾的Output操作運算式要在所有的 Input操作運算式被輸入前輸出。我們看下面這個例子:
int main(int __argc, char* __argv[])
{
int __in1 = 8, __in2 = 4, __out = 3;
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=a"(__out)
: "r" (__in1), "r" (__in2));
return 0;
}
此例中,%0對應的就是Output操作運算式,它被指定的寄存器是%eax,整個Instruction List的第一條指令popl %0,編譯後就成為popl %eax,這時%eax的內容已經被修改,隨後在Instruction List後,GCC會通過movl %eax, address_of_out這條指令將%eax的內容放置到Output變數__out中。對於本例中的兩個Input操作運算式而言,它們的寄存器約 束為"r",即要求GCC為其指定合適的寄存器,然後在Instruction List之前將__in1和__in2的內容放入被選出的寄存器中,如果它們中的一個選擇了已經被__out指定的寄存器%eax,假如是__in1,那麼GCC在Instruction List之前會插入指令movl address_of_in1, %eax,那麼隨後popl %eax指令就修改了%eax的值,此時%eax中存放的已經不是Input變數__in1的值了,那麼隨後的movl %1, %%esi指令,將不會按照我們的本意——即將__in1的值放入%esi中——而是將__out的值放入%esi中了。
下面就是本例的編譯結果,很明顯,GCC為__in2選擇了和__out相同的寄存器%eax,這與我們的初衷不符。
main:
pushl %ebp
movl %esp, %ebp
subl $12, %esp
movl $8, -4(%ebp)
movl $4, -8(%ebp)
movl $3, -12(%ebp)
movl -4(%ebp), %edx # __in1使用寄存器%edx
movl -8(%ebp), %eax # __in2使用寄存器%eax
#APP
popl %eax
movl %edx, %esi
movl %eax, %edi
#NO_APP
movl %eax, %eax
movl %eax, -12(%ebp) # __out使用寄存器%eax
movl $0, %eax
leave
ret
為了避免這種情況,我們必須向GCC聲明這一點,要求GCC為所有的Input操作運算式指定別的寄存器,方法就是在Output操作運算式"=a" (__out)的操作約束中加入&約束,由於GCC規定等號(=)約束必須放在第一個,所以我們寫作"=&a"(__out)。
下面是我們將&約束加入之後編譯的結果:
main:
pushl %ebp
movl %esp, %ebp
subl $12, %esp
movl $8, -4(%ebp)
movl $4, -8(%ebp)
movl $3, -12(%ebp)
movl -4(%ebp), %edx #__in1使用寄存器%edx
movl -8(%ebp), %eax
movl %eax, %ecx # __in2使用寄存器%ecx
#APP
popl %eax
movl %edx, %esi
movl %ecx, %edi
#NO_APP
movl %eax, %eax
movl %eax, -12(%ebp) #__out使用寄存器%eax
movl $0, %eax
leave
ret
OK!這下好了,完全與我們的意圖吻合。
如 果一個Output操作運算式的寄存器約束被指定為某個寄存器,只有當至少存在一個Input操作運算式的寄存器約束為可選約束時,(可選約束的意思是可以從多個寄存器中選取一個,或使用非寄存器方式),比如"r"或"g"時,此Output操作運算式使用&修飾才有意義。如果你為所有的 Input操作運算式指定了固定的寄存器,或使用記憶體/立即數約束,則此Output操作運算式使用&修飾沒有任何意義。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&a"(__out)
: "m" (__in1), "c" (__in2));
此例中的Output操作運算式完全沒有必要使用&來修飾,因為__in1和__in2都被指定了固定的寄存器,或使用了記憶體方式,GCC無從選擇。
但如果你已經為某個Output操作運算式指定了&修飾,並指定了某個固定的寄存器,你就不能再為任何Input操作運算式指定這個寄存器,否則會出現編譯錯誤。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&a"(__out)
: "a" (__in1), "c" (__in2));
本例中,由於__out已經指定了寄存器%eax,同時使用了符號&修飾,則再為__in1指定寄存器%eax就是非法的。
反過來,你也可以為Output指定可選約束,比如"r","g"等,讓GCC為其選擇到底使用哪個寄存器,還是使用記憶體方式,GCC在選擇的時候,會首先排除掉已經被Input操作運算式使用的所有寄存器,然後在剩下的寄存器中選擇,或乾脆使用記憶體方式。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&r"(__out)
: "a" (__in1), "c" (__in2));
本例中,由於__out指定了約束"r",即讓GCC為其決定使用哪一格寄存器,而寄存器%eax和%ecx已經被__in1和__in2使用,那麼GCC在為__out選擇的時候,只會在%ebx和%edx中選擇。
前3 個修飾符只能用在Output操作運算式中,而百分號[%]修飾符恰恰相反,只能用在Input操作運算式中,用於向GCC聲明:“當前Input操作表達式中的C/C++運算式可以和下一個Input操作運算式中的C/C++運算式互換”。這個修飾符號一般用於符合交換律運算,比如加(+),乘(*), 與(&),或()等等。我們看一個例子:
int main(int __argc, char* __argv[])
{
int __in1 = 8, __in2 = 4, __out = 3;
__asm__ ("addl %1, %0\n\t"
: "=r"(__out)
: "%r" (__in1), "0" (__in2));
return 0;
}
在此例中,由於指令是一個加法運算,相當於等式__out = __in1 + __in2,而它與等式__out = __in2 + __in1沒有什麼不同。所以使用百分號修飾,讓GCC知道__in1和__in2可以互換,也就是說GCC可以自動將本例的內聯彙編改變為:
__asm__ ("addl %1, %0\n\t"
: "=r"(__out)
: "%r" (__in2), "0" (__in1));
修飾符 Input/Output 意義
= O 表示此Output操作運算式是Write-Only的
+ O 表示此Output操作運算式是Read-Write的
& O 表示此Output操作運算式獨佔為其指定的寄存器
% I 表示此Input操作運算式中的C/C++運算式可以和下一個Input操作運算式中的C/C++運算式互換
4. 占位符
什麼叫占位符?我們看一看下面這個例子:
__asm__ ("addl %1, %0\n\t"
: "=a"(__out)
: "m" (__in1), "a" (__in2));
這個例子中的%0和%1就是占位符。每一個占位符對應一個Input/Output操作運算式。我們在之前已經提到,GCC規定一個內聯彙編語句最多可以有 10個Input/Output操作運算式,然後按照它們被列出的順序依次賦予編號0到9。對於占位元符中的數字而言,和這些編號是對應的。
由於占位符前面使用一個百分號(%),為了區別占位符和寄存器,GCC規定在帶有C/C++運算式的內聯彙編中,"Instruction List"中直接寫出的寄存器前必須使用兩個百分號(%%)。
GCC對其進行編譯的時候,會將每一個占位符替換為對應的Input/Output操作運算式所指定的寄存器/記憶體位址/立即數。比如在上例中,占位符%0對應 Output操作運算式"=a"(__out),而"=a"(__out)指定的寄存器為%eax,所以把占位符%0替換為%eax,占位符%1對應 Input操作運算式"m"(__in1),而"m"(__in1)被指定為記憶體操作,所以把占位元符%1替換為變數__in1的記憶體位址。
也許有人認為,在上面這個例子中,完全可以不使用%0,而是直接寫%%eax,就像這樣:
__asm__ ("addl %1, %%eax\n\t"
: "=a"(__out)
: "m" (__in1), "a" (__in2));
和 上面使用占位符%0沒有什麼不同,那麼使用占位符%0就沒有什麼意義。確實,兩者生成的代碼完全相同,但這並不意味著這種情況下占位元符沒有意義。因為如果不使用占位符,那麼當有一天你想把變數__out的寄存器約束由a改為b時,那麼你也必須將addl指令中的%%eax改為%%ebx,也就是說你需要同 時修改兩個地方,而如果你使用占位符,你只需要修改一次就夠了。另外,如果你不使用占位符,將不利於代碼的清晰性。在上例中,如果你使用占位符,那麼你一眼就可以得知,addl指令的第二個運算元內容最終會輸出到變數__out中;否則,如果你不用占位符,而是直接將addl指令的第2個運算元寫為%% eax,那麼你需要考慮一下才知道它最終需要輸出到變數__out中。這是占位符最粗淺的意義。畢竟在這種情況下,你完全可以不用。
但對於這些情況來說,不用占位元符就完全不行了:
首先,我們看一看上例中的第1個Input操作運算式"m"(__in1),它被GCC替換之後,表現為addl address_of_in1, %%eax,__in1的地址是什麼?編譯時才知道。所以我們完全無法直接在指令中去寫出__in1的位址,這時使用占位符,交給GCC在編譯時進行替 代,就可以解決這個問題。所以這種情況下,我們必須使用占位符。
其次,如果上例中的Output操作運算式"=a"(__out)改為" =r"(__out),那麼__out在究竟使用那麼寄存器只有到編譯時才能通過GCC來決定,既然在我們寫代碼的時候,我們不知道究竟哪個寄存器被選 擇,我們也就不能直接在指令中寫出寄存器的名稱,而只能通過占位符替代來解決。
5. Clobber/Modify
有時候,你想通知GCC當前內聯彙編語句可能會對某些寄存器或記憶體進行修改,希望GCC在編譯時能夠將這一點考慮進去。那麼你就可以在Clobber/Modify域聲明這些寄存器或記憶體。
這種情況一般發生在一個寄存器出現在"Instruction List",但卻不是由Input/Output操作運算式所指定的,也不是在一些Input/Output操作運算式使用"r","g"約束時由GCC 為其選擇的,同時此寄存器被"Instruction List"中的指令修改,而這個寄存器只是供當前內聯彙編臨時使用的情況。比如:
__asm__ ("movl %0, %%ebx" : : "a"(__foo) : "bx");
寄存器%ebx出現在"Instruction List中",並且被movl指令修改,但卻未被任何Input/Output操作運算式指定,所以你需要在Clobber/Modify域指定"bx",以讓GCC知道這一點。
因為你在Input/Output操作運算式所指定的寄存器,或當你為一些Input/Output操作運算式使用"r","g"約束,讓GCC為你選擇一個寄存器時,GCC對這些寄存器是非常清楚的——它知道這些寄存器是被修改的,你根本不需要在Clobber/Modify域再聲明它們。但除此之外, GCC對剩下的寄存器中哪些會被當前的內聯彙編修改一無所知。所以如果你真的在當前內聯彙編指令中修改了它們,那麼就最好在Clobber/Modify 中聲明它們,讓GCC針對這些寄存器做相應的處理。否則有可能會造成寄存器的不一致,從而造成程式執行錯誤。
在Clobber/Modify域中指定這些寄存器的方法很簡單,你只需要將寄存器的名字使用雙引號(" ")引起來。如果有多個寄存器需要聲明,你需要在任意兩個聲明之間用逗號隔開。比如:
__asm__ ("movl %0, %%ebx; popl %%ecx" : : "a"(__foo) : "bx", "cx" );
這些串包括:
聲明的串 代表的寄存器
"al","ax","eax" %eax
"bl","bx","ebx" %ebx
"cl","cx","ecx" %ecx
"dl","dx","edx" %edx
"si","esi" %esi
"di", "edi" %edi
由上表可以看出,你只需要使用"ax","bx","cx","dx","si","di"就可以了,因為其他的都和它們中的一個是等價的。
如果你在一個內聯彙編語句的Clobber/Modify域向GCC聲明某個寄存器內容發生了改變,GCC在編譯時,如果發現這個被聲明的寄存器的內容在此 內聯彙編語句之後還要繼續使用,那麼GCC會首先將此寄存器的內容保存起來,然後在此內聯彙編語句的相關生成代碼之後,再將其內容恢復。我們來看兩個例子,然後對比一下它們之間的區別。
這個例子中聲明了寄存器%ebx內容發生了改變:
$ cat example7.c
int main(int __argc, char* __argv[])
{
int in = 8;
__asm__ ("addl %0, %%ebx"
: /* no output */
: "a" (in) : "bx");
return 0;
}
$ gcc -O -S example7.c
$ cat example7.s
main:
pushl %ebp
movl %esp, %ebp
pushl %ebx # %ebx內容被保存
movl $8, %eax
#APP
addl %eax, %ebx
#NO_APP
movl $0, %eax
movl (%esp), %ebx # %ebx內容被恢復
leave
ret
下面這個例子的C源碼與上一個例子除了沒有聲明%ebx寄存器發生了改變之外,其他都相同。
$ cat example8.c
int main(int __argc, char* __argv[])
{
int in = 8;
__asm__ ("addl %0, %%ebx"
: /* no output */
: "a" (in) );
return 0;
}
$ gcc -O -S example8.c
$ cat example8.s
main:
pushl %ebp
movl %esp, %ebp
movl $8, %eax
#APP
addl %eax, %ebx
#NO_APP
movl $0, %eax
popl %ebp
ret
仔細對比一下example7.s和example8.s,你就會明白在Clobber/Modify域聲明一個寄存器的意義。
另外需要注意的是,如果你在Clobber/Modify域聲明了一個寄存器,那麼這個寄存器將不能再被用做當前內聯彙編語句的Input/Output操 作運算式的寄存器約束,如果Input/Output操作運算式的寄存器約束被指定為"r"或"g",GCC也不會選擇已經被聲明在 Clobber/Modify中的寄存器。比如:
__asm__ ("movl %0, %%ebx" : : "a"(__foo) : "ax", "bx");
此例中,由於Output操作運算式"a"(__foo)的寄存器約束已經指定了%eax寄存器,那麼再在Clobber/Modify域中指定"ax"就是非法的。編譯時,GCC會給出編譯錯誤。
除 了寄存器的內容會被改變,記憶體的內容也可以被修改。如果一個內聯彙編語句"Instruction List"中的指令對記憶體進行了修改,或者在此內聯彙編出現的地方記憶體內容可能發生改變,而被改變的記憶體位址你沒有在其Output操作運算式使用"m" 約束,這種情況下你需要使用在Clobber/Modify域使用字串"memory"向GCC聲明:“在這裏,記憶體發生了,或可能發生了改變”。例 如:
void * memset(void * s, char c, size_t count)
{
__asm__("cld\n\t"
"rep\n\t"
"stosb"
: /* no output */
: "a" (c),"D" (s),"c" (count)
: "cx","di","memory");
return s;
}
此 例實現了標準函數庫memset,其內聯彙編中的stosb對記憶體進行了改動,而其被修改的記憶體位址s被指定裝入%edi,沒有任何Output操作表達式使用了"m"約束,以指定記憶體位址s處的內容發生了改變。所以在其Clobber/Modify域使用"memory"向GCC聲明:記憶體內容發生了變 動。
如果一個內聯彙編語句的Clobber/Modify域存在"memory",那麼GCC會保證在此內聯彙編之前,如果某個記憶體的內 容被裝入了寄存器,那麼在這個內聯彙編之後,如果需要使用這個記憶體處的內容,就會直接到這個記憶體處重新讀取,而不是使用被存放在寄存器中的拷貝。因為這個時候寄存器中的拷貝已經很可能和記憶體處的內容不一致了。
這只是使用"memory"時,GCC會保證做到的一點,但這並不是全部。因為使用"memory"是向GCC聲明記憶體發生了變化,而記憶體發生變化帶來的影響並不止這一點。比如我們在前面講到的例子:
int main(int __argc, char* __argv[])
{
int* __p = (int*)__argc;
(*__p) = 9999;
__asm__("":::"memory");
if((*__p) == 9999)
return 5;
return (*__p);
}
本 例中,如果沒有那條內聯彙編語句,那個if語句的判斷條件就完全是一句廢話。GCC在優化時會意識到這一點,而直接只生成return 5的彙編代碼,而不會再生成if語句的相關代碼,而不會生成return (*__p)的相關代碼。但你加上了這條內聯彙編語句,它除了聲明記憶體變化之外,什麼都沒有做。但GCC此時就不能簡單的認為它不需要判斷都知道 (*__p)一定與9999相等,它只有老老實實生成這條if語句的彙編代碼,一起相關的兩個return語句相關代碼。
當一個內聯彙編指令中包含影響eflags寄存器中的條件標誌(也就是那些Jxx等跳轉指令要參考的標誌位元,比如,進位元標誌,0標誌等),那麼需要在 Clobber/Modify域中使用"cc"來聲明這一點。這些指令包括adc, div,popfl,btr,bts等等,另外,當包含call指令時,由於你不知道你所call的函數是否會修改條件標誌,為了穩妥起見,最好也使用 "cc"。
我很少在相關資料中看到有關"cc"的確切用法,只有一份文檔提到了它,但還不是i386平臺的,只是說"cc"是處理器平臺 相關的,並非所有的平臺都支持它,但即使在不支持它的平臺上,使用它也不會造成編譯錯誤。我做了一些實驗,但發現使用"cc"和不使用"cc"所生成的代碼沒有任何不同。但Linux 2.4的相關代碼中用到了它。如果誰知道在i386平臺上"cc"的細節,請和我聯繫。
另外,還可以在 Clobber/Modify域指定數位0到9,以聲明第n個Input/Output操作運算式所使用的寄存器發生了變化,但正如我們在前面所提到的,如果你為某個Input/Output操作運算式指定了寄存器,或使用"g","r"等約束讓GCC為其選擇寄存器,GCC已經知道哪個寄存器內容發生了 變化,所以這麼做沒有什麼意義;我也作了相關的試驗,沒有發現使用它會對GCC生成的彙編代碼有任何影響,至少在i386平臺上是這樣。Linux 2.4的所有i386平臺相關內聯彙編代碼中都沒有使用這一點,但S390平臺相關代碼中有用到,但由於我對S390彙編沒有任何概念,所以,也不知道這麼做的意義何在。
先說明語法,內嵌彙編語法如下:
語法可參考http://topic.csdn.net/u/20090521/11/35609357-57b9-4c7c-af6a-04a76eef49a3.html
__asm__(彙編語句範本: 輸出部分: 輸入部分: 破壞描述部分)共四個部分:彙編語句範本,輸出部分,輸入部分,破壞描述部分,各部分使用":"格開,彙編語句範本必不可少,其他三部分可選,如果使用了後面的部分,而前面部分為空,也需要用":"格開,相應部分內容為空。例如:
__asm__ __volatile__("cli": : :"memory")
我一開始不理解其中的"memory"是什麼意思,後來在網上看到說是設置“記憶體屏障”的,並找到了關於"memory"的一段闡述:”memory強制gcc編譯器假設RAM所有記憶體單元均被彙編指令修改,這樣cpu中的registers和cache中已緩存的記憶體單元中的資料將作廢。cpu將不得不在需要的時候重新讀取記憶體中的資料。這就阻止了cpu又將registers,cache中的資料用於去優化指令,而避免去訪問記憶體。”
以下內容源自:http://hi.baidu.com/hilyjiang/blog/item/7db5077a8180dbec2e73b380.html
__asm__ __volatile__ GCC的內嵌彙編語法 AT&T組合語言語法(一)
開發一個OS,儘管絕大部分代碼只需要用C/C++等高階語言就可以了,但至少和硬體相關部分的代碼需要使用組合語言,另外,由於啟動部分的代碼有大小限制,使用精練的彙編可以縮小目標代碼的Size。另外,對於某些需要被經常調用的代碼,使用彙編來寫可以提高性能。所以我們必須瞭解組合語言,即使你有可能並不喜歡它。
如果你是電腦專業的話,在大學裏你應該學習過Intel格式的8086/80386彙編,這裏就不再討論。如果我們選擇的OS開發工具是GCC以及GAS的話,就必須瞭解AT&T組合語言語法,因為GCC/GAS只支援這種彙編語法。
本書不會去討論8086/80386的彙編編程,這類的書籍很多,你可以參考它們。這裏只會討論AT&T的彙編語法,以及GCC的內嵌彙編語法。
--------------------------------------------------------------------------------
0.3.2 Syntax
1.寄存器引用
引用寄存器要在寄存器號前加百分號%,如“movl %eax, %ebx”。
80386有如下寄存器:
8個32-bit寄存器 %eax,%ebx,%ecx,%edx,%edi,%esi,%ebp,%esp;
8個16-bit寄存器,它們事實上是上面8個32-bit寄存器的低16位:%ax,%bx,%cx,%dx,%di,%si,%bp,%sp;
8個8-bit寄存器:%ah,%al,%bh,%bl,%ch,%cl,%dh,%dl。它們事實上是寄存器%ax,%bx,%cx,%dx的高8位和低8位;
6個段寄存器:%cs(code),%ds(data),%ss(stack), %es,%fs,%gs;
3個控制寄存器:%cr0,%cr2,%cr3;
6個debug寄存器:%db0,%db1,%db2,%db3,%db6,%db7;
2個測試寄存器:%tr6,%tr7;
8個浮點寄存器棧:%st(0),%st(1),%st(2),%st(3),%st(4),%st(5),%st(6),%st(7)。
2. 運算元順序
運算元排列是從源(左)到目的(右),如“movl %eax(源), %ebx(目的)”
3. 立即數
使用立即數,要在數前面加符號$, 如“movl $0x04, %ebx”
或者:
para = 0x04
movl $para, %ebx
指令執行的結果是將立即數04h裝入寄存器ebx。
4. 符號常數
符號常數直接引用如
value: .long 0x12a3f2de
movl value , %ebx
指令執行的結果是將常數0x12a3f2de裝入寄存器ebx。
引用符號位址在符號前加符號$, 如“movl $value, % ebx”則是將符號value的位址裝入寄存器ebx。
5. 運算元的長度
運算元的長度用加在指令後的符號表示b(byte, 8-bit), w(word, 16-bits), l(long, 32-bits),如“movb %al, %bl”,“movw %ax, %bx”,“movl %eax, %ebx ”。
如 果沒有指定運算元長度的話,編譯器將按照目標運算元的長度來設置。比如指令“mov %ax, %bx”,由於目標運算元bx的長度為word,那麼編譯器將把此指令等同於“movw %ax, %bx”。同樣道理,指令“mov $4, %ebx”等同於指令“movl $4, %ebx”,“push %al”等同於“pushb %al”。對於沒有指定運算元長度,但編譯器又無法猜測的指令,編譯器將會報錯,比如指令“push $4”。
6. 符號擴展和零擴展指令
絕大多數面向80386的AT&T彙編指令與Intel格式的彙編指令都是相同的,符號擴展指令和零擴展指令則是僅有的不同格式指令。
符號擴展指令和零擴展指令需要指定源運算元長度和目的運算元長度,即使在某些指令中這些運算元是隱含的。
在AT& T語法中,符號擴展和零擴展指令的格式為,基本部分"movs"和"movz"(對應Intel語法的movsx和movzx),後面跟上源運算元長度和 目的運算元長度。movsbl意味著movs (from)byte (to)long;movbw意味著movs (from)byte (to)word;movswl意味著movs (from)word (to)long。對於movz指令也一樣。比如指令“movsbl %al, %edx”意味著將al寄存器的內容進行符號擴展後放置到edx寄存器中。
其他的Intel格式的符號擴展指令還有:
cbw -- sign-extend byte in %al to word in %ax;
cwde -- sign-extend word in %ax to long in %eax;
cwd -- sign-extend word in %ax to long in %dx:%ax;
cdq -- sign-extend dword in %eax to quad in %edx:%eax;
對應的AT&T語法的指令為cbtw,cwtl,cwtd,cltd。
7. 調用和跳轉指令
段內調用和跳轉指令為"call","ret"和"jmp",段間調用和跳轉指令為"lcall","lret"和"ljmp"。
段間調用和跳轉指令的格式為“lcall/ljmp $SECTION, $OFFSET”,而段間返回指令則為“lret $STACK-ADJUST”。
8. 首碼
操作碼首碼被用在下列的情況:
字串重複操作指令(rep,repne);
指定被操作的段(cs,ds,ss,es,fs,gs);
進行匯流排加鎖(lock);
指定位址和操作的大小(data16,addr16);
在AT&T彙編語法中,操作碼首碼通常被單獨放在一行,後面不跟任何運算元。例如,對於重複scas指令,其寫法為:
repne
scas
上述操作碼首碼的意義和用法如下:
指定被操作的段首碼為cs,ds,ss,es,fs,和gs。在AT&T語法中,只需要按照section:memory-operand的格式就指定了相應的段首碼。比如:lcall %cs:realmode_swtch
運算元/位址大小首碼是“data16”和"addr16",它們被用來在32-bit運算元/地址代碼中指定16-bit的運算元/地址。
總 線加鎖首碼“lock”,它是為了在多處理器環境中,保證在當前指令執行期間禁止一切中斷。這個首碼僅僅對ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG,DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD,XCHG指令有效,如果將Lock首碼用在其他指令之前,將會引起異常。
字串重複操作首碼"rep","repe","repne"用來讓字串操作重複“%ecx”次。
9. 記憶體引用
Intel語法的間接記憶體引用的格式為:
section:[base+index*scale+displacement]
而在AT&T語法中對應的形式為:
section:displacement(base,index,scale)
其 中,base和index是任意的32-bit base和index寄存器。scale可以取值1,2,4,8。如果不指定scale值,則預設值為1。section可以指定任意的段寄存器作為段首碼,默認的段寄存器在不同的情況下不一樣。如果你在指令中指定了默認的段首碼,則編譯器在目標代碼中不會產生此段首碼代碼。
下面是一些例子:
-4(%ebp):base=%ebp,displacement=-4,section沒有指定,由於base=%ebp,所以默認的section=%ss,index,scale沒有指定,則index為0。
foo(,%eax,4):index=%eax,scale=4,displacement=foo。其他域沒有指定。這裏默認的section=%ds。
foo(,1):這個運算式引用的是指標foo指向的位址所存放的值。注意這個運算式中沒有base和index,並且只有一個逗號,這是一種異常語法,但卻合法。
%gs:foo:這個運算式引用的是放置于%gs段裏變數foo的值。
如果call和jump操作在運算元前指定首碼“*”,則表示是一個絕對位址調用/跳轉,也就是說jmp/call指令指定的是一個絕對位址。如果沒有指定"*",則運算元是一個相對位址。
任何指令如果其運算元是一個記憶體操作,則指令必須指定它的操作尺寸(byte,word,long),也就是說必須帶有指令尾碼(b,w,l)。
.3 GCC Inline ASM
GCC 支持在C/C++代碼中嵌入彙編代碼,這些彙編代碼被稱作GCC Inline ASM——GCC內聯彙編。這是一個非常有用的功能,有利於我們將一些C/C++語法無法表達的指令直接潛入C/C++代碼中,另外也允許我們直接寫 C/C++代碼中使用彙編編寫簡潔高效的代碼。
1.基本內聯彙編
GCC中基本的內聯彙編非常易懂,我們先來看兩個簡單的例子:
__asm__("movl %esp,%eax"); // 看起來很熟悉吧
或者是
__asm__("
movl $1,%eax // SYS_exit
xor %ebx,%ebx
int $0x80
");
或
__asm__(
"movl $1,%eax\r\t" \
"xor %ebx,%ebx\r\t" \
"int $0x80" \
);
基本內聯彙編的格式是
__asm__ __volatile__("Instruction List");
1、__asm__
__asm__是GCC關鍵字asm的巨集定義:
#define __asm__ asm
__asm__或asm用來聲明一個內聯彙編運算式,所以任何一個內聯彙編運算式都是以它開頭的,是必不可少的。
2、Instruction List
Instruction List是彙編指令序列。它可以是空的,比如:__asm__ __volatile__(""); 或__asm__ ("");都是完全合法的內聯彙編運算式,只不過這兩條語句沒有什麼意義。但並非所有Instruction List為空的內聯彙編運算式都是沒有意義的,比如:__asm__ ("":::"memory"); 就非常有意義,它向GCC聲明:“我對記憶體作了改動”,GCC在編譯的時候,會將此因素考慮進去。
我們看一看下面這個例子:
$ cat example1.c
int main(int __argc, char* __argv[])
{
int* __p = (int*)__argc;
(*__p) = 9999;
//__asm__("":::"memory");
if((*__p) == 9999)
return 5;
return (*__p);
}
在 這段代碼中,那條內聯彙編是被注釋掉的。在這條內聯彙編之前,記憶體指標__p所指向的記憶體被賦值為9999,隨即在內聯彙編之後,一條if語句判斷__p 所指向的記憶體與9999是否相等。很明顯,它們是相等的。GCC在優化編譯的時候能夠很聰明的發現這一點。我們使用下面的命令行對其進行編譯:
$ gcc -O -S example1.c
選項-O表示優化編譯,我們還可以指定優化等級,比如-O2表示優化等級為2;選項-S表示將C/C++原始檔案編譯為彙編檔,檔案名和C/C++文件一樣,只不過副檔名由.c變為.s。
我們來查看一下被放在example1.s中的編譯結果,我們這裏僅僅列出了使用gcc 2.96在redhat 7.3上編譯後的相關函數部分彙編代碼。為了保持清晰性,無關的其他代碼未被列出。
$ cat example1.s
main:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax # int* __p = (int*)__argc
movl $9999, (%eax) # (*__p) = 9999
movl $5, %eax # return 5
popl %ebp
ret
參 照一下C源碼和編譯出的彙編代碼,我們會發現彙編代碼中,沒有if語句相關的代碼,而是在賦值語句(*__p)=9999後直接return 5;這是因為GCC認為在(*__p)被賦值之後,在if語句之前沒有任何改變(*__p)內容的操作,所以那條if語句的判斷條件(*__p) == 9999肯定是為true的,所以GCC就不再生成相關代碼,而是直接根據為true的條件生成return 5的彙編代碼(GCC使用eax作為保存返回值的寄存器)。
我們現在將example1.c中內聯彙編的注釋去掉,重新編譯,然後看一下相關的編譯結果。
$ gcc -O -S example1.c
$ cat example1.s
main:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax # int* __p = (int*)__argc
movl $9999, (%eax) # (*__p) = 9999
#APP
# __asm__("":::"memory")
#NO_APP
cmpl $9999, (%eax) # (*__p) == 9999 ?
jne .L3 # false
movl $5, %eax # true, return 5
jmp .L2
.p2align 2
.L3:
movl (%eax), %eax
.L2:
popl %ebp
ret
由於內聯彙編語句__asm__("":::"memory")向GCC聲明,在此內聯彙編語句出現的位置記憶體內容可能了改變,所以GCC在編譯時就不能像剛才那樣處理。這次,GCC老老實實的將if語句生成了彙編代碼。
可能有人會質疑:為什麼要使用__asm__("":::"memory")向GCC聲明記憶體發生了變化?明明“Instruction List”是空的,沒有任何對記憶體的操作,這樣做只會增加GCC生成彙編代碼的數量。
確 實,那條內聯彙編語句沒有對記憶體作任何操作,事實上它確實什麼都沒有做。但影響記憶體內容的不僅僅是你當前正在運行的程式。比如,如果你現在正在操作的記憶體是一塊記憶體映射,映射的內容是週邊I/O設備寄存器。那麼操作這塊記憶體的就不僅僅是當前的程式,I/O設備也會去操作這塊記憶體。既然兩者都會去操作同一塊 記憶體,那麼任何一方在任何時候都不能對這塊記憶體的內容想當然。所以當你使用高階語言C/C++寫這類程式的時候,你必須讓編譯器也能夠明白這一點,畢竟高 級語言最終要被編譯為彙編代碼。
你可能已經注意到了,這次輸出的彙編結果中,有兩個符號:#APP和#NO_APP,GCC將內聯彙編語句中"Instruction List"所列出的指令放在#APP和#NO_APP之間,由於__asm__("":::"memory")中“Instruction List”為空,所以#APP和#NO_APP中間也沒有任何內容。但我們以後的例子會更加清楚的表現這一點。
關於為什麼內聯彙編__asm__("":::"memory")是一條聲明記憶體改變的語句,我們後面會詳細討論。
剛才我們花了大量的內容來討論"Instruction List"為空是的情況,但在實際的編程中,"Instruction List"絕大多數情況下都不是空的。它可以有1條或任意多條彙編指令。
當 在"Instruction List"中有多條指令的時候,你可以在一對引號中列出全部指令,也可以將一條或幾條指令放在一對引號中,所有指令放在多對引號中。如果是前者,你可以將每一條指令放在一行,如果要將多條指令放在一行,則必須用分號(;)或換行符(\n,大多數情況下\n後還要跟一個\t,其中\n是為了換行,\t是為了 空出一個tab寬度的空格)將它們分開。比如:
__asm__("movl %eax, %ebx
sti
popl %edi
subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti
popl %edi; subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi
subl %ecx, %ebx");
都是合法的寫法。如果你將指令放在多對引號中,則除了最後一對引號之外,前面的所有引號裏的最後一條指令之後都要有一個分號(;)或(\n)或(\n\t)。比如:
__asm__("movl %eax, %ebx
sti\n"
"popl %edi;"
"subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t"
"popl %edi; subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi\n"
"subl %ecx, %ebx");
__asm__("movl %eax, %ebx; sti\n\t popl %edi;" "subl %ecx, %ebx");
都是合法的。
上述原則可以歸結為:
任意兩個指令間要麼被分號(;)分開,要麼被放在兩行;
放在兩行的方法既可以從通過\n的方法來實現,也可以真正的放在兩行;
可以使用1對或多對引號,每1對引號裏可以放任一多條指令,所有的指令都要被放到引號中。
在基本內聯彙編中,“Instruction List”的書寫的格式和你直接在彙編檔中寫非內聯彙編沒有什麼不同,你可以在其中定義Label,定義對齊(.align n ),定義段(.section name )。例如:
__asm__(".align 2\n\t"
"movl %eax, %ebx\n\t"
"test %ebx, %ecx\n\t"
"jne error\n\t"
"sti\n\t"
"error: popl %edi\n\t"
"subl %ecx, %ebx");
上面例子的格式是Linux內聯代碼常用的格式,非常整齊。也建議大家都使用這種格式來寫內聯彙編代碼。
3、__volatile__
__volatile__是GCC關鍵字volatile的巨集定義:
#define __volatile__ volatile
__volatile__ 或volatile是可選的,你可以用它也可以不用它。如果你用了它,則是向GCC聲明“不要動我所寫的Instruction List,我需要原封不動的保留每一條指令”,否則當你使用了優化選項(-O)進行編譯時,GCC將會根據自己的判斷決定是否將這個內聯彙編運算式中的指 令優化掉。
那麼GCC判斷的原則是什麼?我不知道(如果有哪位朋友清楚的話,請告訴我)。我試驗了一下,發現一條內聯彙編語句如果是基本 內聯彙編的話(即只有“Instruction List”,沒有Input/Output/Clobber的內聯彙編,我們後面將會討論這一點),無論你是否使用__volatile__來修飾, GCC 2.96在優化編譯時,都會原封不動的保留內聯彙編中的“Instruction List”。但或許我的試驗的例子並不充分,所以這一點並不能夠得到保證。
為了保險起見,如果你不想讓GCC的優化影響你的內聯彙編代碼,你最好在前面都加上__volatile__,而不要依賴於編譯器的原則,因為即使你非常瞭解當前編譯器的優化原則,你也無法保證這種原則將來不會發生變化。而__volatile__的含義卻是恒定的。
2、帶有C/C++運算式的內聯彙編
GCC允許你通過C/C++運算式指定內聯彙編中"Instrcuction List"中指令的輸入和輸出,你甚至可以不關心到底使用哪個寄存器被使用,完全靠GCC來安排和指定。這一點可以讓程式師避免去考慮有限的寄存器的使用,也可以提高目標代碼的效率。
我們先來看幾個例子:
__asm__ (" " : : : "memory" ); // 前面提到的
__asm__ ("mov %%eax, %%ebx" : "=b"(rv) : "a"(foo) : "eax", "ebx");
__asm__ __volatile__("lidt %0": "=m" (idt_descr));
__asm__("subl %2,%0\n\t"
"sbbl %3,%1"
: "=a" (endlow), "=d" (endhigh)
: "g" (startlow), "g" (starthigh), "0" (endlow), "1" (endhigh));
怎麼樣,有點印象了吧,是不是也有點暈?沒關係,下面討論完之後你就不會再暈了。(當然,也有可能更暈^_^)。討論開始——
帶有C/C++運算式的內聯彙編格式為:
__asm__ __volatile__("Instruction List" : Output : Input : Clobber/Modify);
從中我們可以看出它和基本內聯彙編的不同之處在於:它多了3個部分(Input,Output,Clobber/Modify)。在括弧中的4個部分通過冒號(:)分開。
這4個部分都不是必須的,任何一個部分都可以為空,其規則為:
如 果Clobber/Modify為空,則其前面的冒號(:)必須省略。比如__asm__("mov %%eax, %%ebx" : "=b"(foo) : "a"(inp) : )就是非法的寫法;而__asm__("mov %%eax, %%ebx" : "=b"(foo) : "a"(inp) )則是正確的。
如果Instruction List為空,則Input,Output,Clobber/Modify可以不為空,也可以為空。比如__asm__ ( " " : : : "memory" );和__asm__(" " : : );都是合法的寫法。
如 果Output,Input,Clobber/Modify都為空,Output,Input之前的冒號(:)既可以省略,也可以不省略。如果都省略,則此彙編退化為一個基本內聯彙編,否則,仍然是一個帶有C/C++運算式的內聯彙編,此時"Instruction List"中的寄存器寫法要遵守相關規定,比如寄存器前必須使用兩個百分號(%%),而不是像基本彙編格式一樣在寄存器前只使用一個百分號(%)。比如 __asm__( " mov %%eax, %%ebx" : : );__asm__( " mov %%eax, %%ebx" : )和__asm__( " mov %eax, %ebx" )都是正確的寫法,而__asm__( " mov %eax, %ebx" : : );__asm__( " mov %eax, %ebx" : )和__asm__( " mov %%eax, %%ebx" )都是錯誤的寫法。
如果Input,Clobber/Modify為空,但Output不為空,Input前的冒號(:)既可以省略,也可以不省略。比如 __asm__( " mov %%eax, %%ebx" : "=b"(foo) : );__asm__( " mov %%eax, %%ebx" : "=b"(foo) )都是正確的。
如果後面的部分不為空,而前面的部分為空,則前面的冒號(:)都必須保留,否則無法說 明不為空的部分究竟是第幾部分。比如, Clobber/Modify,Output為空,而Input不為空,則Clobber/Modify前的冒號必須省略(前面的規則),而Output 前的冒號必須為保留。如果Clobber/Modify不為空,而Input和Output都為空,則Input和Output前的冒號都必須保留。比如 __asm__( " mov %%eax, %%ebx" : : "a"(foo) )和__asm__( " mov %%eax, %%ebx" : : : "ebx" )。
從上面的規則可以看到另外一個事實,區分一個內聯彙編是基本格式的還是帶有C/C++運算式格式的,其規則在於在"Instruction List"後是否有冒號(:)的存在,如果沒有則是基本格式的,否則,則是帶有C/C++運算式格式的。
兩種格式對寄存器語法的要求不同:基本格式要求寄存器前只能使用一個百分號(%),這一點和非內聯彙編相同;而帶有C/C++運算式格式則要求寄存器前必須使用兩個百分號(%%),其原因我們會在後面討論。
1. Output
Output用來指定當前內聯彙編語句的輸出。我們看一看這個例子:
__asm__("movl %%cr0, %0": "=a" (cr0));
這 個內聯彙編語句的輸出部分為"=r"(cr0),它是一個“操作運算式”,指定了一個輸出操作。我們可以很清楚得看到這個輸出操作由兩部分組成:括弧括住 的部分(cr0)和引號引住的部分"=a"。這兩部分都是每一個輸出操作必不可少的。括弧括住的部分是一個C/C++運算式,用來保存內聯彙編的一個輸出值,其操作就等於C/C++的相等賦值cr0 = output_value,因此,括弧中的輸出運算式只能是C/C++的左值運算式,也就是說它只能是一個可以合法的放在C/C++賦值操作中等號(=) 左邊的運算式。那麼右值output_value從何而來呢?
答案是引號中的內容,被稱作“操作約束”(Operation Constraint),在這個例子中操作約束為"=a",它包含兩個約束:等號(=)和字母a,其中等號(=)說明括弧中左值運算式cr0是一個 Write-Only的,只能夠被作為當前內聯彙編的輸入,而不能作為輸入。而字母a是寄存器EAX / AX / AL的簡寫,說明cr0的值要從eax寄存器中獲取,也就是說cr0 = eax,最終這一點被轉化成彙編指令就是movl %eax, address_of_cr0。現在你應該清楚了吧,操作約束中會給出:到底從哪個寄存器傳遞值給cr0。
另外,需要特別說明的是,很多文檔都聲明,所有輸出操作的操作約束必須包含一個等號(=),但GCC的文檔中卻很清楚的聲明,並非如此。因為等號(=)約束說明當前的運算式是一個 Write-Only的,但另外還有一個符號——加號(+)用來說明當前運算式是一個Read-Write的,如果一個操作約束中沒有給出這兩個符號中的任何一個,則說明當前運算式是Read-Only的。因為對於輸出操作來說,肯定是必須是可寫的,而等號(=)和加號(+)都表示可寫,只不過加號(+) 同時也表示是可讀的。所以對於一個輸出操作來說,其操作約束只需要有等號(=)或加號(+)中的任意一個就可以了。
二者的區別是:等號(=)表示當前操作運算式指定了一個純粹的輸出操作,而加號(+)則表示當前操作運算式不僅僅只是一個輸出操作還是一個輸入操作。但無論是等號(=)約束還是加號(+)約束所約束的操作運算式都只能放在Output域中,而不能被用在Input域中。
另外,有些文檔聲明:儘管GCC文檔中提供了加號(+)約束,但在實際的編譯中通不過;我不知道老版本會怎麼樣,我在GCC 2.96中對加號(+)約束的使用非常正常。
我們通過一個例子看一下,在一個輸出操作中使用等號(=)約束和加號(+)約束的不同。
$ cat example2.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %%cr0, %0":"=a" (cr0));
return 0;
}
$ gcc -S example2.c
$ cat example2.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
#APP
movl %cr0, %eax
#NO_APP
movl %eax, %eax
movl %eax, -4(%ebp) # cr0 = %eax
movl $0, %eax
leave
ret
這個例子是使用等號(=)約束的情況,變數cr0被放在記憶體-4(%ebp)的位置,所以指令mov %eax, -4(%ebp)即表示將%eax的內容輸出到變數cr0中。
下面是使用加號(+)約束的情況:
$ cat example3.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %%cr0, %0" : "+a" (cr0));
return 0;
}
$ gcc -S example3.c
$ cat example3.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
movl -4(%ebp), %eax # input ( %eax = cr0 )
#APP
movl %cr0, %eax
#NO_APP
movl %eax, -4(%ebp) # output (cr0 = %eax )
movl $0, %eax
leave
ret
從編譯的結果可以看出,當使用加號(+)約束的時候,cr0不僅作為輸出,還作為輸入,所使用寄存器都是寄存器約束(字母a,表示使用eax寄存器)指定的。關於寄存器約束我們後面討論。
在Output域中可以有多個輸出操作運算式,多個操作運算式中間必須用逗號(,)分開。例如:
__asm__(
"movl %%eax, %0 \n\t"
"pushl %%ebx \n\t"
"popl %1 \n\t"
"movl %1, %2"
: "+a"(cr0), "=b"(cr1), "=c"(cr2));
2、Input
Input域的內容用來指定當前內聯彙編語句的輸入。我們看一看這個例子:
__asm__("movl %0, %%db7" : : "a" (cpu->db7));
例中Input域的內容為一個運算式"a"[cpu->db7),被稱作“輸入運算式”,用來表示一個對當前內聯彙編的輸入。
像輸出運算式一樣,一個輸入運算式也分為兩部分:帶括弧的部分(cpu->db7)和帶引號的部分"a"。這兩部分對於一個內聯彙編輸入運算式來說也是必不可少的。
括 號中的運算式cpu->db7是一個C/C++語言的運算式,它不必是一個左值運算式,也就是說它不僅可以是放在C/C++賦值操作左邊的運算式, 還可以是放在C/C++賦值操作右邊的運算式。所以它可以是一個變數,一個數位,還可以是一個複雜的運算式(比如a+b/c*d)。比如上例可以改為: __asm__("movl %0, %%db7" : : "a" (foo)),__asm__("movl %0, %%db7" : : "a" (0x1000))或__asm__("movl %0, %%db7" : : "a" (va*vb/vc))。
引號號中的部分是約束部分,和輸出運算式約束不同的是,它不允許指定加號(+)約束和等號(=)約束,也就是說它只能是默認的Read-Only的。約束中必須指定 一個寄存器約束,例中的字母a表示當前輸入變數cpu->db7要通過寄存器eax輸入到當前內聯彙編中。
我們看一個例子:
$ cat example4.c
int main(int __argc, char* __argv[])
{
int cr0 = 5;
__asm__ __volatile__("movl %0, %%cr0"::"a" (cr0));
return 0;
}
$ gcc -S example4.c
$ cat example4.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, -4(%ebp) # cr0 = 5
movl -4(%ebp), %eax # %eax = cr0
#APP
movl %eax, %cr0
#NO_APP
movl $0, %eax
leave
ret
我們從編譯出的彙編代碼可以看到,在"Instruction List"之前,GCC按照我們的輸入約束"a",將變數cr0的內容裝入了eax寄存器。
3. Operation Constraint
每一個Input和Output運算式都必須指定自己的操作約束Operation Constraint,我們這裏來討論在80386平臺上所可能使用的操作約束。
1、寄存器約束
當你當前的輸入或輸入需要借助一個寄存器時,你需要為其指定一個寄存器約束。你可以直接指定一個寄存器的名字,比如:
__asm__ __volatile__("movl %0, %%cr0"::"eax" (cr0));
也可以指定一個縮寫,比如:
__asm__ __volatile__("movl %0, %%cr0"::"a" (cr0));
如果你指定一個縮寫,比如字母a,則GCC將會根據當前操作運算式中C/C++運算式的寬度決定使用%eax,還是%ax或%al。比如:
unsigned short __shrt;
__asm__ ("mov %0,%%bx" : : "a"(__shrt));
由於變數__shrt是16-bit short類型,則編譯出來的彙編代碼中,則會讓此變數使用%ex寄存器。編譯結果為:
movw -2(%ebp), %ax # %ax = __shrt
#APP
movl %ax, %bx
#NO_APP
無論是Input,還是Output操作運算式約束,都可以使用寄存器約束。
下表中列出了常用的寄存器約束的縮寫。
約束 Input/Output 意義
r I,O 表示使用一個通用寄存器,由GCC在%eax/%ax/%al, %ebx/%bx/%bl, %ecx/%cx/%cl, %edx/%dx/%dl中選取一個GCC認為合適的。
q I,O 表示使用一個通用寄存器,和r的意義相同。
a I,O 表示使用%eax / %ax / %al
b I,O 表示使用%ebx / %bx / %bl
c I,O 表示使用%ecx / %cx / %cl
d I,O 表示使用%edx / %dx / %dl
D I,O 表示使用%edi / %di
S I,O 表示使用%esi / %si
f I,O 表示使用浮點寄存器
t I,O 表示使用第一個浮點寄存器
u I,O 表示使用第二個浮點寄存器
2、記憶體約束
如果一個Input/Output操作運算式的C/C++運算式表現為一個記憶體位址,不想借助於任何寄存器,則可以使用記憶體約束。比如:
__asm__ ("lidt %0" : "=m"(__idt_addr)); 或 __asm__ ("lidt %0" : :"m"(__idt_addr));
我們看一下它們分別被放在一個C原始檔案中,然後被GCC編譯後的結果:
$ cat example5.c
// 本例中,變數sh被作為一個記憶體輸入
int main(int __argc, char* __argv[])
{
char* sh = (char*)&__argc;
__asm__ __volatile__("lidt %0" : : "m" (sh));
return 0;
}
$ gcc -S example5.c
$ cat example5.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
leal 8(%ebp), %eax
movl %eax, -4(%ebp) # sh = (char*) &__argc
#APP
lidt -4(%ebp)
#NO_APP
movl $0, %eax
leave
ret
$ cat example6.c
// 本例中,變數sh被作為一個記憶體輸出
int main(int __argc, char* __argv[])
{
char* sh = (char*)&__argc;
__asm__ __volatile__("lidt %0" : "=m" (sh));
return 0;
}
$ gcc -S example6.c
$ cat example6.s
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
leal 8(%ebp), %eax
movl %eax, -4(%ebp) # sh = (char*) &__argc
#APP
lidt -4(%ebp)
#NO_APP
movl $0, %eax
leave
ret
首先,你會注意到,在這兩個例子中,變數sh沒有借助任何寄存器,而是直接參與了指令lidt的操作。
其次,通過仔細觀察,你會發現一個驚人的事實,兩個例子編譯出來的彙編代碼是一樣的!雖然,一個例子中變數sh作為輸入,而另一個例子中變數sh作為輸出。這是怎麼回事?
原來,使用記憶體方式進行輸入輸出時,由於不借助寄存器,所以GCC不會按照你的聲明對其作任何的輸入輸出處理。GCC只會直接拿來用,究竟對這個C/C++運算式而言是輸入還是輸出,完全依賴與你寫在"Instruction List"中的指令對其操作的指令。
由 於上例中,對其操作的指令為lidt,lidt指令的運算元是一個輸入型的運算元,所以事實上對變數sh的操作是一個輸入操作,即使你把它放在 Output域也不會改變這一點。所以,對此例而言,完全符合語意的寫法應該是將sh放在Input域,儘管放在Output域也會有正確的執行結果。
所 以,對於記憶體約束類型的操作運算式而言,放在Input域還是放在Output域,對編譯結果是沒有任何影響的,因為本來我們將一個操作運算式放在 Input域或放在Output域是希望GCC能為我們自動通過寄存器將運算式的值輸入或輸出。既然對於記憶體約束類型的操作運算式來說,GCC不會自動為 它做任何事情,那麼放在哪兒也就無所謂了。但從程式師的角度而言,為了增強代碼的可讀性,最好能夠把它放在符合實際情況的地方。
約束 Input/Output 意義
m I,O 表示使用系統所支援的任何一種記憶體方式,不需要借助寄存器
__asm__ __volatile__ GCC的內嵌彙編語法 AT&T組合語言語法(二)
3、立即數約束
如果一個Input/Output操作運算式的C/C++運算式是一個數字常數,不想借助於任何寄存器,則可以使用立即數約束。
由於立即數在C/C++中只能作為右值,所以對於使用立即數約束的運算式而言,只能放在Input域。
比如:__asm__ __volatile__("movl %0, %%eax" : : "i" (100) );
立即數約束很簡單,也很容易理解,我們在這裏就不再贅述。
約束 Input/Output 意義
i I 表示輸入運算式是一個立即數(整數),不需要借助任何寄存器
F I 表示輸入運算式是一個立即數(浮點數),不需要借助任何寄存器
4、通用約束
約束 Input/Output 意義
g I,O 表示可以使用通用寄存器,記憶體,立即數等任何一種處理方式。
0,1,2,3,4,5,6,7,8,9 I 表示和第n個操作運算式使用相同的寄存器/記憶體。
通用約束g是一個非常靈活的約束,當程式師認為一個C/C++運算式在實際的操作中,究竟使用寄存器方式,還是使用記憶體方式或立即數方式並無所謂時,或者程式師想實現一個靈活的範本,讓GCC可以根據不同的C/C++運算式生成不同的訪問方式時,就可以使用通用約束g。比如:
#define JUST_MOV(foo) __asm__ ("movl %0, %%eax" : : "g"(foo))
JUST_MOV(100)和JUST_MOV(var)則會讓編譯器產生不同的代碼。
int main(int __argc, char* __argv[])
{
JUST_MOV(100);
return 0;
}
編譯後生成的代碼為:
main:
pushl %ebp
movl %esp, %ebp
#APP
movl $100, %eax
#NO_APP
movl $0, %eax
popl %ebp
ret
很明顯這是立即數方式。而下一個例子:
int main(int __argc, char* __argv[])
{
JUST_MOV(__argc);
return 0;
}
經編譯後生成的代碼為:
main:
pushl %ebp
movl %esp, %ebp
#APP
movl 8(%ebp), %eax
#NO_APP
movl $0, %eax
popl %ebp
ret
這個例子是使用記憶體方式。
一個帶有C/C++運算式的內聯彙編,其操作運算式被按照被列出的順序編號,第一個是0,第2個是1,依次類推,GCC最多允許有10個操作運算式。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=a"(__out)
: "r" (__in1), "r" (__in2));
此例中,__out所在的Output操作運算式被編號為0,"r"(__in1)被編號為1,"r"(__in2)被編號為2。
再如:
__asm__ ("movl %%eax, %%ebx" : : "a"(__in1), "b"(__in2));
此例中,"a"(__in1)被編號為0,"b"(__in2)被編號為1。
如果某個Input操作運算式使用數字0到9中的一個數字(假設為1)作為它的操作約束,則等於向GCC聲明:“我要使用和編號為1的Output操作表達式相同的寄存器(如果Output操作運算式1使用的是寄存器),或相同的記憶體位址(如果Output操作運算式1使用的是記憶體)”。上面的描述包含兩個限定:數位0到數位9作為操作約束只能用在Input操作運算式中,被指定的操作運算式(比如某個Input操作運算式使用數位1作為約束,那麼被指定的 就是編號為1的操作運算式)只能是Output操作運算式。
由於GCC規定最多只能有10個Input/Output操作運算式,所以事實上數字9作為操作約束永遠也用不到,因為Output操作運算式排在Input操作運算式的前面,那麼如果有一個Input操作運算式指定了數字9作為 操作約束的話,那麼說明Output操作運算式的數量已經至少為10個了,那麼再加上這個Input操作運算式,則至少為11個了,以及超出GCC的限 制。
5、Modifier Characters(修飾符)
等號(=)和加號(+)用於對Output操作運算式的修飾,一個Output操作運算式要麼被等號(=)修飾,要麼被加號(+)修飾,二者必居其一。使用等號(=)說明此Output操作運算式是Write- Only的,使用加號(+)說明此Output操作運算式是Read-Write的。它們必須被放在約束字串的第一個字母。比如"a="(foo)是非 法的,而"+g"(foo)則是合法的。
當使用加號(+)的時候,此Output運算式等價於使用等號(=)約束加上一個Input運算式。比如
__asm__ ("movl %0, %%eax; addl %%eax, %0" : "+b"(foo)) 等價於
__asm__ ("movl %1, %%eax; addl %%eax, %0" : "=b"(foo) : "b"(foo))
但如果使用後一種寫法,"Instruction List"中的別名也要相應的改動。關於別名,我們後面會討論。
像等號(=)和加號(+)修飾符一樣,符號(&)也只能用於對Output操作運算式的修飾。當使用它進行修飾時,等於向GCC聲明:"GCC不得 為任何Input操作運算式分配與此Output操作運算式相同的寄存器"。其原因是&修飾符意味著被其修飾的Output操作運算式要在所有的 Input操作運算式被輸入前輸出。我們看下面這個例子:
int main(int __argc, char* __argv[])
{
int __in1 = 8, __in2 = 4, __out = 3;
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=a"(__out)
: "r" (__in1), "r" (__in2));
return 0;
}
此例中,%0對應的就是Output操作運算式,它被指定的寄存器是%eax,整個Instruction List的第一條指令popl %0,編譯後就成為popl %eax,這時%eax的內容已經被修改,隨後在Instruction List後,GCC會通過movl %eax, address_of_out這條指令將%eax的內容放置到Output變數__out中。對於本例中的兩個Input操作運算式而言,它們的寄存器約 束為"r",即要求GCC為其指定合適的寄存器,然後在Instruction List之前將__in1和__in2的內容放入被選出的寄存器中,如果它們中的一個選擇了已經被__out指定的寄存器%eax,假如是__in1,那麼GCC在Instruction List之前會插入指令movl address_of_in1, %eax,那麼隨後popl %eax指令就修改了%eax的值,此時%eax中存放的已經不是Input變數__in1的值了,那麼隨後的movl %1, %%esi指令,將不會按照我們的本意——即將__in1的值放入%esi中——而是將__out的值放入%esi中了。
下面就是本例的編譯結果,很明顯,GCC為__in2選擇了和__out相同的寄存器%eax,這與我們的初衷不符。
main:
pushl %ebp
movl %esp, %ebp
subl $12, %esp
movl $8, -4(%ebp)
movl $4, -8(%ebp)
movl $3, -12(%ebp)
movl -4(%ebp), %edx # __in1使用寄存器%edx
movl -8(%ebp), %eax # __in2使用寄存器%eax
#APP
popl %eax
movl %edx, %esi
movl %eax, %edi
#NO_APP
movl %eax, %eax
movl %eax, -12(%ebp) # __out使用寄存器%eax
movl $0, %eax
leave
ret
為了避免這種情況,我們必須向GCC聲明這一點,要求GCC為所有的Input操作運算式指定別的寄存器,方法就是在Output操作運算式"=a" (__out)的操作約束中加入&約束,由於GCC規定等號(=)約束必須放在第一個,所以我們寫作"=&a"(__out)。
下面是我們將&約束加入之後編譯的結果:
main:
pushl %ebp
movl %esp, %ebp
subl $12, %esp
movl $8, -4(%ebp)
movl $4, -8(%ebp)
movl $3, -12(%ebp)
movl -4(%ebp), %edx #__in1使用寄存器%edx
movl -8(%ebp), %eax
movl %eax, %ecx # __in2使用寄存器%ecx
#APP
popl %eax
movl %edx, %esi
movl %ecx, %edi
#NO_APP
movl %eax, %eax
movl %eax, -12(%ebp) #__out使用寄存器%eax
movl $0, %eax
leave
ret
OK!這下好了,完全與我們的意圖吻合。
如 果一個Output操作運算式的寄存器約束被指定為某個寄存器,只有當至少存在一個Input操作運算式的寄存器約束為可選約束時,(可選約束的意思是可以從多個寄存器中選取一個,或使用非寄存器方式),比如"r"或"g"時,此Output操作運算式使用&修飾才有意義。如果你為所有的 Input操作運算式指定了固定的寄存器,或使用記憶體/立即數約束,則此Output操作運算式使用&修飾沒有任何意義。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&a"(__out)
: "m" (__in1), "c" (__in2));
此例中的Output操作運算式完全沒有必要使用&來修飾,因為__in1和__in2都被指定了固定的寄存器,或使用了記憶體方式,GCC無從選擇。
但如果你已經為某個Output操作運算式指定了&修飾,並指定了某個固定的寄存器,你就不能再為任何Input操作運算式指定這個寄存器,否則會出現編譯錯誤。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&a"(__out)
: "a" (__in1), "c" (__in2));
本例中,由於__out已經指定了寄存器%eax,同時使用了符號&修飾,則再為__in1指定寄存器%eax就是非法的。
反過來,你也可以為Output指定可選約束,比如"r","g"等,讓GCC為其選擇到底使用哪個寄存器,還是使用記憶體方式,GCC在選擇的時候,會首先排除掉已經被Input操作運算式使用的所有寄存器,然後在剩下的寄存器中選擇,或乾脆使用記憶體方式。比如:
__asm__ ("popl %0 \n\t"
"movl %1, %%esi \n\t"
"movl %2, %%edi \n\t"
: "=&r"(__out)
: "a" (__in1), "c" (__in2));
本例中,由於__out指定了約束"r",即讓GCC為其決定使用哪一格寄存器,而寄存器%eax和%ecx已經被__in1和__in2使用,那麼GCC在為__out選擇的時候,只會在%ebx和%edx中選擇。
前3 個修飾符只能用在Output操作運算式中,而百分號[%]修飾符恰恰相反,只能用在Input操作運算式中,用於向GCC聲明:“當前Input操作表達式中的C/C++運算式可以和下一個Input操作運算式中的C/C++運算式互換”。這個修飾符號一般用於符合交換律運算,比如加(+),乘(*), 與(&),或()等等。我們看一個例子:
int main(int __argc, char* __argv[])
{
int __in1 = 8, __in2 = 4, __out = 3;
__asm__ ("addl %1, %0\n\t"
: "=r"(__out)
: "%r" (__in1), "0" (__in2));
return 0;
}
在此例中,由於指令是一個加法運算,相當於等式__out = __in1 + __in2,而它與等式__out = __in2 + __in1沒有什麼不同。所以使用百分號修飾,讓GCC知道__in1和__in2可以互換,也就是說GCC可以自動將本例的內聯彙編改變為:
__asm__ ("addl %1, %0\n\t"
: "=r"(__out)
: "%r" (__in2), "0" (__in1));
修飾符 Input/Output 意義
= O 表示此Output操作運算式是Write-Only的
+ O 表示此Output操作運算式是Read-Write的
& O 表示此Output操作運算式獨佔為其指定的寄存器
% I 表示此Input操作運算式中的C/C++運算式可以和下一個Input操作運算式中的C/C++運算式互換
4. 占位符
什麼叫占位符?我們看一看下面這個例子:
__asm__ ("addl %1, %0\n\t"
: "=a"(__out)
: "m" (__in1), "a" (__in2));
這個例子中的%0和%1就是占位符。每一個占位符對應一個Input/Output操作運算式。我們在之前已經提到,GCC規定一個內聯彙編語句最多可以有 10個Input/Output操作運算式,然後按照它們被列出的順序依次賦予編號0到9。對於占位元符中的數字而言,和這些編號是對應的。
由於占位符前面使用一個百分號(%),為了區別占位符和寄存器,GCC規定在帶有C/C++運算式的內聯彙編中,"Instruction List"中直接寫出的寄存器前必須使用兩個百分號(%%)。
GCC對其進行編譯的時候,會將每一個占位符替換為對應的Input/Output操作運算式所指定的寄存器/記憶體位址/立即數。比如在上例中,占位符%0對應 Output操作運算式"=a"(__out),而"=a"(__out)指定的寄存器為%eax,所以把占位符%0替換為%eax,占位符%1對應 Input操作運算式"m"(__in1),而"m"(__in1)被指定為記憶體操作,所以把占位元符%1替換為變數__in1的記憶體位址。
也許有人認為,在上面這個例子中,完全可以不使用%0,而是直接寫%%eax,就像這樣:
__asm__ ("addl %1, %%eax\n\t"
: "=a"(__out)
: "m" (__in1), "a" (__in2));
和 上面使用占位符%0沒有什麼不同,那麼使用占位符%0就沒有什麼意義。確實,兩者生成的代碼完全相同,但這並不意味著這種情況下占位元符沒有意義。因為如果不使用占位符,那麼當有一天你想把變數__out的寄存器約束由a改為b時,那麼你也必須將addl指令中的%%eax改為%%ebx,也就是說你需要同 時修改兩個地方,而如果你使用占位符,你只需要修改一次就夠了。另外,如果你不使用占位符,將不利於代碼的清晰性。在上例中,如果你使用占位符,那麼你一眼就可以得知,addl指令的第二個運算元內容最終會輸出到變數__out中;否則,如果你不用占位符,而是直接將addl指令的第2個運算元寫為%% eax,那麼你需要考慮一下才知道它最終需要輸出到變數__out中。這是占位符最粗淺的意義。畢竟在這種情況下,你完全可以不用。
但對於這些情況來說,不用占位元符就完全不行了:
首先,我們看一看上例中的第1個Input操作運算式"m"(__in1),它被GCC替換之後,表現為addl address_of_in1, %%eax,__in1的地址是什麼?編譯時才知道。所以我們完全無法直接在指令中去寫出__in1的位址,這時使用占位符,交給GCC在編譯時進行替 代,就可以解決這個問題。所以這種情況下,我們必須使用占位符。
其次,如果上例中的Output操作運算式"=a"(__out)改為" =r"(__out),那麼__out在究竟使用那麼寄存器只有到編譯時才能通過GCC來決定,既然在我們寫代碼的時候,我們不知道究竟哪個寄存器被選 擇,我們也就不能直接在指令中寫出寄存器的名稱,而只能通過占位符替代來解決。
5. Clobber/Modify
有時候,你想通知GCC當前內聯彙編語句可能會對某些寄存器或記憶體進行修改,希望GCC在編譯時能夠將這一點考慮進去。那麼你就可以在Clobber/Modify域聲明這些寄存器或記憶體。
這種情況一般發生在一個寄存器出現在"Instruction List",但卻不是由Input/Output操作運算式所指定的,也不是在一些Input/Output操作運算式使用"r","g"約束時由GCC 為其選擇的,同時此寄存器被"Instruction List"中的指令修改,而這個寄存器只是供當前內聯彙編臨時使用的情況。比如:
__asm__ ("movl %0, %%ebx" : : "a"(__foo) : "bx");
寄存器%ebx出現在"Instruction List中",並且被movl指令修改,但卻未被任何Input/Output操作運算式指定,所以你需要在Clobber/Modify域指定"bx",以讓GCC知道這一點。
因為你在Input/Output操作運算式所指定的寄存器,或當你為一些Input/Output操作運算式使用"r","g"約束,讓GCC為你選擇一個寄存器時,GCC對這些寄存器是非常清楚的——它知道這些寄存器是被修改的,你根本不需要在Clobber/Modify域再聲明它們。但除此之外, GCC對剩下的寄存器中哪些會被當前的內聯彙編修改一無所知。所以如果你真的在當前內聯彙編指令中修改了它們,那麼就最好在Clobber/Modify 中聲明它們,讓GCC針對這些寄存器做相應的處理。否則有可能會造成寄存器的不一致,從而造成程式執行錯誤。
在Clobber/Modify域中指定這些寄存器的方法很簡單,你只需要將寄存器的名字使用雙引號(" ")引起來。如果有多個寄存器需要聲明,你需要在任意兩個聲明之間用逗號隔開。比如:
__asm__ ("movl %0, %%ebx; popl %%ecx" : : "a"(__foo) : "bx", "cx" );
這些串包括:
聲明的串 代表的寄存器
"al","ax","eax" %eax
"bl","bx","ebx" %ebx
"cl","cx","ecx" %ecx
"dl","dx","edx" %edx
"si","esi" %esi
"di", "edi" %edi
由上表可以看出,你只需要使用"ax","bx","cx","dx","si","di"就可以了,因為其他的都和它們中的一個是等價的。
如果你在一個內聯彙編語句的Clobber/Modify域向GCC聲明某個寄存器內容發生了改變,GCC在編譯時,如果發現這個被聲明的寄存器的內容在此 內聯彙編語句之後還要繼續使用,那麼GCC會首先將此寄存器的內容保存起來,然後在此內聯彙編語句的相關生成代碼之後,再將其內容恢復。我們來看兩個例子,然後對比一下它們之間的區別。
這個例子中聲明了寄存器%ebx內容發生了改變:
$ cat example7.c
int main(int __argc, char* __argv[])
{
int in = 8;
__asm__ ("addl %0, %%ebx"
: /* no output */
: "a" (in) : "bx");
return 0;
}
$ gcc -O -S example7.c
$ cat example7.s
main:
pushl %ebp
movl %esp, %ebp
pushl %ebx # %ebx內容被保存
movl $8, %eax
#APP
addl %eax, %ebx
#NO_APP
movl $0, %eax
movl (%esp), %ebx # %ebx內容被恢復
leave
ret
下面這個例子的C源碼與上一個例子除了沒有聲明%ebx寄存器發生了改變之外,其他都相同。
$ cat example8.c
int main(int __argc, char* __argv[])
{
int in = 8;
__asm__ ("addl %0, %%ebx"
: /* no output */
: "a" (in) );
return 0;
}
$ gcc -O -S example8.c
$ cat example8.s
main:
pushl %ebp
movl %esp, %ebp
movl $8, %eax
#APP
addl %eax, %ebx
#NO_APP
movl $0, %eax
popl %ebp
ret
仔細對比一下example7.s和example8.s,你就會明白在Clobber/Modify域聲明一個寄存器的意義。
另外需要注意的是,如果你在Clobber/Modify域聲明了一個寄存器,那麼這個寄存器將不能再被用做當前內聯彙編語句的Input/Output操 作運算式的寄存器約束,如果Input/Output操作運算式的寄存器約束被指定為"r"或"g",GCC也不會選擇已經被聲明在 Clobber/Modify中的寄存器。比如:
__asm__ ("movl %0, %%ebx" : : "a"(__foo) : "ax", "bx");
此例中,由於Output操作運算式"a"(__foo)的寄存器約束已經指定了%eax寄存器,那麼再在Clobber/Modify域中指定"ax"就是非法的。編譯時,GCC會給出編譯錯誤。
除 了寄存器的內容會被改變,記憶體的內容也可以被修改。如果一個內聯彙編語句"Instruction List"中的指令對記憶體進行了修改,或者在此內聯彙編出現的地方記憶體內容可能發生改變,而被改變的記憶體位址你沒有在其Output操作運算式使用"m" 約束,這種情況下你需要使用在Clobber/Modify域使用字串"memory"向GCC聲明:“在這裏,記憶體發生了,或可能發生了改變”。例 如:
void * memset(void * s, char c, size_t count)
{
__asm__("cld\n\t"
"rep\n\t"
"stosb"
: /* no output */
: "a" (c),"D" (s),"c" (count)
: "cx","di","memory");
return s;
}
此 例實現了標準函數庫memset,其內聯彙編中的stosb對記憶體進行了改動,而其被修改的記憶體位址s被指定裝入%edi,沒有任何Output操作表達式使用了"m"約束,以指定記憶體位址s處的內容發生了改變。所以在其Clobber/Modify域使用"memory"向GCC聲明:記憶體內容發生了變 動。
如果一個內聯彙編語句的Clobber/Modify域存在"memory",那麼GCC會保證在此內聯彙編之前,如果某個記憶體的內 容被裝入了寄存器,那麼在這個內聯彙編之後,如果需要使用這個記憶體處的內容,就會直接到這個記憶體處重新讀取,而不是使用被存放在寄存器中的拷貝。因為這個時候寄存器中的拷貝已經很可能和記憶體處的內容不一致了。
這只是使用"memory"時,GCC會保證做到的一點,但這並不是全部。因為使用"memory"是向GCC聲明記憶體發生了變化,而記憶體發生變化帶來的影響並不止這一點。比如我們在前面講到的例子:
int main(int __argc, char* __argv[])
{
int* __p = (int*)__argc;
(*__p) = 9999;
__asm__("":::"memory");
if((*__p) == 9999)
return 5;
return (*__p);
}
本 例中,如果沒有那條內聯彙編語句,那個if語句的判斷條件就完全是一句廢話。GCC在優化時會意識到這一點,而直接只生成return 5的彙編代碼,而不會再生成if語句的相關代碼,而不會生成return (*__p)的相關代碼。但你加上了這條內聯彙編語句,它除了聲明記憶體變化之外,什麼都沒有做。但GCC此時就不能簡單的認為它不需要判斷都知道 (*__p)一定與9999相等,它只有老老實實生成這條if語句的彙編代碼,一起相關的兩個return語句相關代碼。
當一個內聯彙編指令中包含影響eflags寄存器中的條件標誌(也就是那些Jxx等跳轉指令要參考的標誌位元,比如,進位元標誌,0標誌等),那麼需要在 Clobber/Modify域中使用"cc"來聲明這一點。這些指令包括adc, div,popfl,btr,bts等等,另外,當包含call指令時,由於你不知道你所call的函數是否會修改條件標誌,為了穩妥起見,最好也使用 "cc"。
我很少在相關資料中看到有關"cc"的確切用法,只有一份文檔提到了它,但還不是i386平臺的,只是說"cc"是處理器平臺 相關的,並非所有的平臺都支持它,但即使在不支持它的平臺上,使用它也不會造成編譯錯誤。我做了一些實驗,但發現使用"cc"和不使用"cc"所生成的代碼沒有任何不同。但Linux 2.4的相關代碼中用到了它。如果誰知道在i386平臺上"cc"的細節,請和我聯繫。
另外,還可以在 Clobber/Modify域指定數位0到9,以聲明第n個Input/Output操作運算式所使用的寄存器發生了變化,但正如我們在前面所提到的,如果你為某個Input/Output操作運算式指定了寄存器,或使用"g","r"等約束讓GCC為其選擇寄存器,GCC已經知道哪個寄存器內容發生了 變化,所以這麼做沒有什麼意義;我也作了相關的試驗,沒有發現使用它會對GCC生成的彙編代碼有任何影響,至少在i386平臺上是這樣。Linux 2.4的所有i386平臺相關內聯彙編代碼中都沒有使用這一點,但S390平臺相關代碼中有用到,但由於我對S390彙編沒有任何概念,所以,也不知道這麼做的意義何在。
訂閱:
文章 (Atom)